

引言
01
在研究中,我们经常需要比较不同组别在某个连续因变量上的平均差异。传统的方差分析(ANOVA)可以用来评估这些差异,但它忽略了可能影响因变量的其他连续变量。存在其他变量时,可使用协方差分析(ANCOVA)的方法。协方差分析(ANCOVA)可以让我们在比较组间差异时控制一个或多个连续协变量的影响。下面我们来了解下什么是ANCOVA。
什么是ANCOVA
02
ANCOVA(协方差分析)的概念由美国统计学家R. A. Fisher在20世纪30年代提出。ANCOVA结合了方差分析和回归分析的思想,可用于比较不同组的均值,同时控制一个或多个协变量的影响,其核心思想是通过控制潜在的混杂变量,更准确地评估自变量(组别)对因变量的影响。
ANCOVA中有几个关键概念:
因变量 (dependent variable):我们想要研究的结果变量,如考试成绩。从统计学的角度来说,因变量是被检验的变量。从研究角度来说,因变量是研究的效果。
图1 因变量
自变量(independent variable):组别变量,通常是分类变量,如不同的教学方法。
协变量(covariate):指在统计分析中可能影响因变量的变量,但并不是主要关注的自变量。
下面我们来看几个具体的例子:
在教育研究中,研究不同教学方法对学生成绩的影响时,学生的初始能力(如前测成绩)可以作为协变量。虽然主要关注的是教学方法,但初始能力可能影响最终成绩,因此需要控制。
在医学试验中,研究新药对血压的影响时,患者的年龄和体重可以作为协变量。由于这些因素可能会影响血压,因此在比较新药与对照组时需要考虑它们的影响。
在心理学研究中,研究焦虑水平对考试成绩的影响时,学生的学习时间可以作为协变量。学习时间可能影响考试成绩,所以在分析焦虑对成绩的影响时,需要控制学习时间的变化。
在社会科学研究中,在分析不同地区的收入水平对生活满意度的影响时,教育水平可以作为协变量。教育水平可能会影响收入和生活满意度,因此在分析时应将其纳入考虑。
ANCOVA可以简单地表示成一个线性模型:
Y=β0+β1X+β2C+ϵ
其中,Y是因变量,X是自变量,C是协变量,β表示模型参数,ϵ是误差项。
其假设检验为:
零假设(H0):各组的均值在控制了协变量后没有显著差异。
备择假设(H1):至少有一组的均值在控制了协变量后存在显著差异。
ANCOVA的优点是能有效地排除协变量的影响,提供更可靠的结果。
分析步骤
02
下面我们通过一个示例来看下如何进行协方差分析。
假设我们想研究不同教学方法对学生数学成绩的影响,但学生的初始数学能力(前测成绩)不一样。
1. 定义变量
因变量(Y):数学成绩(score)
自变量(X):教学方法(group),有三种方法:A、B、C
协变量(C):数学前测成绩(initial_score)
2. 收集数据
我们收集到了以下数据:

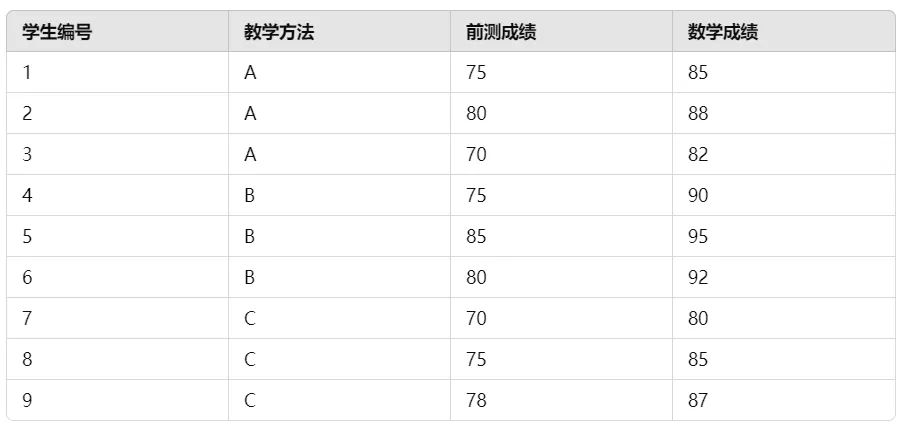
3. 检查数据
在进行ANCOVA之前,需确保:
正态性:检查每组的数学成绩分布。
方差齐性:使用Levene’s检验检查不同组的方差是否相等。
4. 建立模型
在R语言中,我们可以使用以下代码来进行ANCOVA分析:
# 导入数据
data <- data.frame(
student_id = 1:9,
group = factor(c("A", "A", "A", "B", "B", "B", "C", "C", "C")),
initial_score = c(75, 80, 70, 75, 85, 80, 70, 75, 78),
score = c(85, 88, 82, 90, 95, 92, 80, 85, 87)
)
# 进行ANCOVA分析
model <- aov(score ~ group + initial_score, data = data)
summary(model)6. 分析结果
假设输出如下:
Df Sum Sq Mean Sq F value Pr(>F)
group 2 124.22 62.11 89.22 0.000123 ***
initial_score 1 53.19 53.19 76.40 0.000325 ***
Residuals 5 3.48 0.70
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1在这个输出中:
group的p值为0.000123,表明不同教学方法之间的均值差异是显著的。
initial_score的p值为0.000325,表明初始成绩对数学成绩的影响显著。
7. 进行事后检验(post hoc test)
如果想要进一步了解哪些组之间存在显著差异,可以进行Tukey检验:
TukeyHSD(model)输出结果如下:
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = score ~ group + initial_score, data = data)
$group
diff lwr upr p adj
B-A 7.333333 5.116614 9.550053 0.0002827
C-A -1.000000 -3.216719 1.216719 0.3796214
C-B -8.333333 -10.550053 -6.116614 0.0001520数据结果说明:
- 组B的成绩显著高于组A。
- 组C与组A之间没有显著差异。
- 组C的成绩显著低于组B。
8. 结果可视化
可以使用箱线图展示结果:
ggplot(data, aes(x = group, y = score)) +
geom_boxplot(fill = c("lightblue", "lightgreen", "lightpink")) +
labs(title = "不同教学方法的数学成绩比较",
x = "教学方法",
y = "数学成绩") +
theme_minimal()

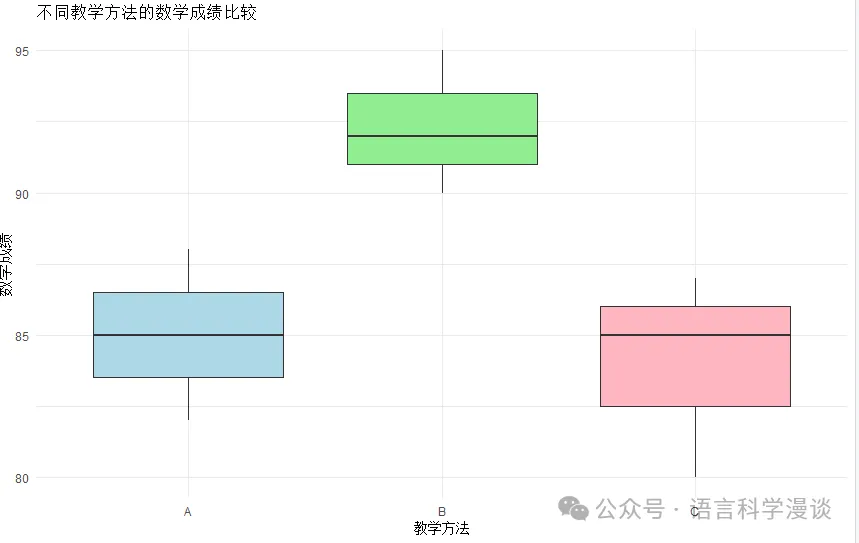
9. 报告结果
在报告中,可以说明以下内容:本研究采用协方差分析(ANCOVA)对不同教学方法对学生数学成绩的影响进行了深入分析。结果显示,教学方法对学生数学成绩的影响极为显著(p < 0.001),表明教学方法的选择对学生的数学学习成效具有重要影响。此外,学生的初始数学能力同样对成绩有显著影响(p < 0.001)。进一步分析发现,与教学方法A相比,教学方法B显著提升了学生的数学成绩,而教学方法C的成绩虽与教学方法A无显著差异,但明显低于教学方法B。这些结果为教育工作者在选择教学方法时提供了有力的实证依据,推荐在教学设计中优先考虑采用教学方法B,以期提高学生的数学成绩。
ANCOVA和ANOVA的区别
04
ANCOVA(协方差分析)和ANOVA(方差分析)都是用于比较组间均值的统计方法,它们的关键区别如下:
1. 协变量的使用
ANCOVA:除了比较自变量(组别)对因变量的影响外,ANCOVA还包括一个或多个协变量(控制变量)。它通过控制协变量的影响,可以更准确的比较组间均值。
ANOVA:仅比较自变量(组别)对因变量的影响,不考虑任何其他变量的影响。
2. 分析目的
ANCOVA:旨在评估自变量对因变量的影响,同时控制潜在的混杂变量。它可以提高统计功效,减少因变量的误差变异。
ANOVA:主要用于确定不同组之间是否存在显著的均值差异,不考虑其他变量的干扰。
3. 模型复杂度
ANCOVA:模型通常更复杂,因为它包括协变量,并需要验证协变量与因变量之间的线性关系。
ANOVA:相对简单,只需要比较组间的均值和方差。
4. 假设检验
ANCOVA:除了需要满足ANOVA的基本假设(如正态性、方差齐性)外,还需检验协变量与因变量之间的线性关系。
ANOVA:主要关注因变量的正态性和各组方差的齐性。
5. 应用场景
ANCOVA:适用于存在潜在混杂变量的研究场景,例如教育、医学研究等。
ANOVA:适用于简单的组间均值比较,没有复杂的协变量控制需求。
下面我们来看一个具体的例子:
假设我们研究不同教学方法对学生数学成绩的影响
1) 使用ANOVA分析时,我们比较三种教学方法(A、B、C)对学生数学成绩的影响,而不考虑任何其他因素。
2) 使用ANCOVA分析时,我们在比较三种教学方法(A、B、C)对数学成绩的影响,同时考虑学生的初始数学能力(前测成绩)作为协变量。
相比之下,ANOVA仅比较教学方法对数学成绩的影响,未考虑初始能力。可能导致得出不准确的结论。ANCOVA比较教学方法的影响,同时控制初始能力,提供了更准确的组间差异评估。
小结
05
本文介绍了统计中的协方差分析(ANCOVA)。协方差分析可以用评估不同组别在特定因变量上的表现,同时控制一个或多个关键协变量的影响。通过这种方法,我们能够更准确地理解不同组别之间的真实差异。然而,使用ANCOVA时,如果协变量的选择不当或数据存在异常值,可能会影响分析结果。后续我们会介绍更多的统计学知识,敬请关注。