
贝叶斯线性回归:概率与预测建模的融合
在古希腊时期,地心说模型是主导宇宙观,将地球置于宇宙中心。希腊天文学家,如托勒密,观察到行星呈现看似不规则的运动,有时甚至会逆行。为解释这一现象,他们引入了本轮概念——小圆在大圆(均轮)上运动——来表示行星轨道。
图1:历史上的地心说(以地球为中心)托勒密宇宙模型图。
托勒密在其著作《天文学大成》中详细阐述了这一系统,运用圆套圆的方法来近似行星的复杂运动。尽管随着本轮数量的增加,模型变得愈发复杂,但它仍能有效预测行星位置。虽然后来被日心说模型取代,但这一模型展示了数学近似的早期应用。
图2:行星绕地球(地球在中心)运行的本轮图示。路径线表示行星轨道(均轮)绕地球运动和轨道内部(本轮)运动的组合。
古代天文学家使用圆套圆模拟行星运动,与此类似傅里叶级数**将复杂模式分解为更简单的组成部分。傅里叶方法利用正弦和余弦波来近似不规则函数,这与本轮用于模拟行星路径的方式相似。通过调整波的频率和振幅,我们能够用简单的、重复的模式精确表示复杂行为,这与古代天文学家使用本轮的方法有异曲同工之妙。
图3:傅里叶级数示意图。
古希腊的本轮和傅里叶的正弦-余弦分解都体现了数学和科学中的一个基本概念:近似。无论是模拟行星运动还是分解复杂函数,目标都是用更简单、更易于管理的组成部分来表示复杂的现实。通过叠加这些组成部分,我们可以创建越来越精确地近似世界的模型。
图4:近似示意图。
在傅里叶级数中,使用的正弦和余弦项越多,就越接近系统的实际行为。这一原理是许多数学建模形式的核心——我们的近似能力使我们能够进行预测、发现模式并理解数据背后的结构。
图5:方波的傅里叶级数近似。
与古代模型和傅里叶分解类似,线性回归是另一种近似变量之间关系的工具。我们从圆和波转向直线——数据的线性近似。
从贝叶斯角度看,线性回归不仅仅是通过数据点拟合一条线。它是一个贝叶斯过程,我们用概率来表达对变量间关系的不确定性。在这种方法中假设不确定性遵循高斯(正态)分布,不是寻找单一的最佳拟合线,而是考虑所有可能的线,根据它们在给定数据下的可能性进行权衡。
高斯分布
高斯分布(正态分布)是贝叶斯线性回归的核心。其钟形曲线代表了数据中的不确定性。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pos = np.random.uniform(-1, 1, size=(16, 1000)).sum(0)
sns.kdeplot(pos, shade=True)
plt.xlabel('position', fontsize=14)
plt.ylabel('Density', fontsize=14)
plt.show()图6:高斯分布示例。
在上述代码中,我们生成了一个16×1000的矩阵,包含从-1到1之间均匀分布的随机值。均匀分布意味着-1到1之间的每个值出现的概率相等。
pos中的每个值是16个随机值的总和。单个均匀分布不是高斯分布,但当将它们相加时根据中心极限定理,结果分布开始呈现高斯分布的特征。
中心极限定理指出,当对大量独立的随机变量求和时(即使它们不是正态分布),总和往往会遵循正态分布,无论原始变量的分布如何。这是因为虽然单个随机值可以均匀地取任何值,但它们的组合总和会平衡极值。当添加更多值时,结果分布将集中在平均值附近。
在贝叶斯推断中,两个高斯分布相乘的结果仍然是一个高斯分布。以下代码演示了这一点:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 定义两个高斯分布
mu1, sigma1 = 0, 1 # 第一个分布的均值和标准差
mu2, sigma2 = 2, 1 # 第二个分布的均值和标准差
# 创建x值
x = np.linspace(-5, 5, 1000)
# 计算两个高斯分布
dist1 = norm.pdf(x, mu1, sigma1)
dist2 = norm.pdf(x, mu2, sigma2)
# 将两个分布相乘(逐元素)
product_dist = dist1 * dist2
# 归一化结果使其成为适当的概率分布
product_dist /= np.trapz(product_dist, x)
# 绘制分布
plt.plot(x, dist1, label="Gaussian 1 (μ=0, σ=1)")
plt.plot(x, dist2, label="Gaussian 2 (μ=2, σ=1)")
plt.plot(x, product_dist, label="Product of Gaussians", linestyle='--')
plt.xlabel('x')
plt.ylabel('Density')
plt.legend()
plt.show()图7:高斯分布乘积示例。
对数乘法通过将乘积转换为和来简化两个高斯分布的乘法。以下代码演示了这一过程:
# 两个正态分布的对数乘法
log_dist1 = np.log(dist1)
log_dist2 = np.log(dist2)
# 相加对数(对数域中的乘法是加法)
log_product_dist = log_dist1 + log_dist2
plt.plot(x, log_dist1, label="Log of Gaussian 1")
plt.plot(x, log_dist2, label="Log of Gaussian 2")
plt.plot(x, log_product_dist, label="Sum of Logs (Log-Multiplication)", linestyle='--')
plt.xlabel('x')
plt.ylabel('Log Density')
plt.legend()
plt.show()图8:高斯分布对数乘法示例。
绿色虚线曲线显示了两个对数高斯分布的和。由于相加对数等同于乘以原始高斯分布,这条曲线代表了两个原始高斯分布乘积的对数。
这个原理在贝叶斯推断中至关重要,因为乘以似然和先验会得到更新的后验信念,反映了观察到的数据和先验知识。
高斯模型
接下来,我们将使用实际数据构建一个线性回归模型。我们将使用Howell1数据集,该数据集可以从以下链接获取:
首先加载并查看数据:
import pandas as pd
df = pd.read_csv("Howell1.csv", sep=";")
df.tail()
"""
height weight age male
539 145.415 31.127751 17.0 1
540 162.560 52.163080 31.0 1
541 156.210 54.062497 21.0 0
542 71.120 8.051258 0.0 1
543 158.750 52.531624 68.0 1
"""该数据集包含544个条目,包括身高、体重、年龄和性别数据。我们将重点关注身高,并过滤掉年龄低于18岁的观察值,因为成年前的身高可能更为复杂:
df = df[df.age > 18]
df.reset_index(drop=True, inplace=True)
现在,让我们观察身高的分布:
plt.hist(df['height'], bins=20, edgecolor='black')
plt.title('Histogram of Height')
plt.xlabel('Height (cm)')
plt.ylabel('Frequency')
plt.show()
图9:身高分布直方图。
从直方图可以看出,身高呈现近似正态分布的特征,这为使用高斯模型提供了基础。在高斯模型中假设身高的每个观察值都由具有均值μ和标准差σ的相同正态分布定义:
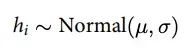
图10:高斯模型示意图。
在贝叶斯建模中,还需要为参数μ和σ指定先验分布。这些先验代表了我们在观察任何数据之前对参数的初始信念。
对于均值μ,可以假设一个正态分布先验:
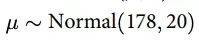
图11:均值μ的先验分布。
这个先验假设平均身高呈正态分布,均值为178厘米,标准差为20厘米。这个选择基于对人类身高的一般认知。
import numpy as np
from scipy import stats
x = np.linspace(100, 250, 100)
plt.plot(x, stats.norm.pdf(x, 178, 20));图12:均值μ的先验分布图。
对于标准差σ,我们可以假设一个均匀分布先验:
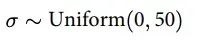
图13:标准差σ的先验分布。
这个先验假设标准差在0到50厘米之间均匀分布。这是一个相对宽松的假设,表明我们对σ的具体值没有强烈的先验信念。
x = np.linspace(-10, 60, 100)
plt.plot(x, stats.uniform.pdf(x, 0, 50));
图14:标准差σ的先验分布图。
选择σ的上界是重要的。为了说明这一点,我们可以比较两个不同标准差的正态分布:
from scipy.stats import norm
mean = 178
std_dev1 = 50
std_dev2 = 100
x = np.linspace(mean - 4*std_dev2, mean + 4*std_dev2, 1000)
dist1 = norm.pdf(x, mean, std_dev1)
dist2 = norm.pdf(x, mean, std_dev2)
plt.plot(x, dist1, label=f'Gaussian 1 (μ={mean}, σ={std_dev1})', color='blue')
plt.plot(x, dist2, label=f'Gaussian 2 (μ={mean}, σ={std_dev2})', color='orange')
plt.title('Comparison of Two Gaussian Distributions')
plt.xlabel('Height (cm)')
plt.ylabel('Density')
plt.legend()
plt.show()图15:不同标准差的高斯分布比较。
从图中可以看出,橙色的分布(σ=100)比蓝色的分布(σ=50)更分散。更重要的是橙色分布包含了负的身高值,这在现实中是不可能的,这就说明了为什么选择适当的σ先验上界很重要。
先验预测模拟是一种用于检验所选先验对可观察数据影响的技术。这种方法在实际观察数据之前基于先验分布模拟数据,以评估先验是否会导致合理的预测。
在贝叶斯统计中,需要模型中所有参数的联合先验分布。如果假设参数μ和σ是独立的,可以将联合先验表示为:
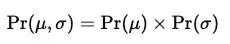
图16:联合先验分布公式。
这意味着关于μ的先验信念独立于关于σ的先验信念。换句话说,了解平均身高并不会改变对标准差的信念,反之亦然。
通过使用联合先验分布的先验预测模拟,可以在这些假设下评估模型预测的身高。这有助于判断所选的先验分布是否合理,以及它们是否会导致符合实际的预测。
线性模型策略
现在,让我们绘制身高和体重的散点图:
plt.scatter(df['weight'], df['height'])
plt.title('Height vs Weight')
plt.ylabel('Height (cm)')
plt.xlabel('Weight (kg)')
plt.show()图17:身高与体重的散点图。
从散点图可以观察到,体重与身高之间存在明显的正相关关系。这表明知道一个人的体重有助于预测他们的身高。
在线性建模中,试图回答这样一个问题:”一个变量(如体重)与结果(如身高)最可能的关系方式是什么?”模型通过给出可能关系的排序列表(后验分布)来回答这个问题,这是基于数据和模型的假设。
线性模型策略使高斯分布的均值通过一个常数、加性关系依赖于预测变量(如体重)。简单来说它假设预测变量的变化以固定、线性的方式影响平均结果。
模型检查所有可能的参数组合,并根据它们的后验概率对它们进行排序,后验概率衡量了每种组合在给定数据的情况下的可能性。
令 x 表示体重测量值(预测变量),¯x 表示 x 的平均值。线性模型可以表示为:
图18:线性模型公式。
在这个模型中:
- [likelihood]:均值μi依赖于每个观察值 i 的特定值。
- [linear model]:均值μi不再是独立参数,而是由两个参数计算得出:α(截距)和β(斜率),以及观察变量 x(预测变量,如体重)。
- 这种关系是确定性的,意味着一旦知道α、β和x,就可以确定μi。
线性模型将这两个参数与数据连接起来,模型基于数据计算α和β最可能的值,使我们能够预测结果如何随预测变量的变化而变化。
[priors]:β的先验特别重要,因为它控制体重和身高之间的关系。关键问题是:应该如何设置β的先验?
一种常见的做法是将β的先验设置为Normal(0, 10)。这意味着假设β可能是正值或负值的概率相等,大多数β值将在-10到+10的范围内。
模拟100种α和β的组合,使用先验β∼Normal(0,10):
np.random.seed(2971)
N = 100 # 要模拟的线条数量
weight = np.linspace(30, 60, 100) # 体重范围
# 模拟alpha和beta值
alpha = np.random.normal(178, 20, N)
beta_normal = np.random.normal(0, 10, N)
xbar = np.mean(weight)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
for i in range(N):
plt.plot(weight, alpha[i] + beta_normal[i] * (weight - xbar), color='black', alpha=0.2)
plt.axhline(y=0, color='black', linestyle='--') # 身高为0的虚线
plt.axhline(y=272, color='black', linestyle='-', lw=0.5) # 世界最高人(272厘米)
plt.xlabel('weight')
plt.ylabel('height')
plt.title('b ~ Normal(0, 10)')
plt.show()图19:使用Normal(0, 10)先验的β模拟结果。
从图19可以看出,使用Normal(0, 10)作为β的先验会导致许多不现实的线性关系。一些线暗示了不合理的身高(如超过400厘米或低于0厘米),这显然不符合人类身高的实际情况。
为了解决这个问题可以考虑使用对数正态分布作为β的先验,即β ~ Log-Normal(0,1)。这确保了β始终为正值,更符合身高与体重正相关的实际情况。
beta_lognormal = np.random.lognormal(0, 1, N)
plt.subplot(1, 2, 2)
for i in range(N):
plt.plot(weight, alpha[i] + beta_lognormal[i] * (weight - xbar), color='black', alpha=0.2)
plt.axhline(y=0, color='black', linestyle='--') # 身高为0的虚线
plt.axhline(y=272, color='black', linestyle='-', lw=0.5) # 世界最高人(272厘米)
plt.xlabel('weight')
plt.title('log(β) ~ Normal(0, 1)')
plt.tight_layout()
plt.show()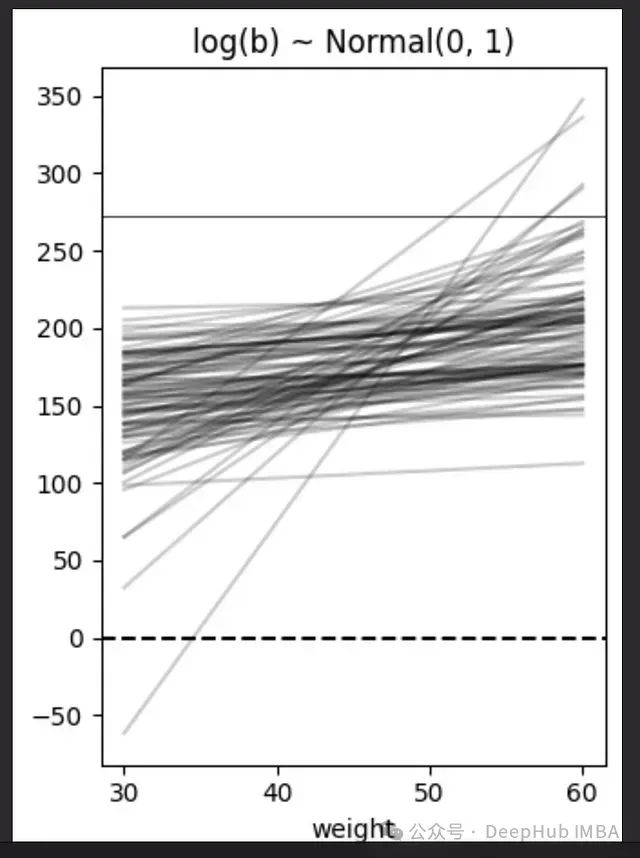
图20:使用Log-Normal(0, 1)先验的β模拟结果。
先验预测模拟帮助检查先验是否能做出合理的预测,从正态先验转换为对数正态先验为β提供了更现实的结果,更好地反映了体重和身高之间的实际关系。
使用最大似然估计来拟合线性模型:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 计算平均体重(x-bar)
xbar = df['weight'].mean()
# 定义负对数似然函数
def negative_log_likelihood(params):
a, b, sigma = params # α(截距),β(斜率),σ(标准差)
mu = a + b * (df['weight'] - xbar) # 均值(μ)的线性模型
residuals = df['height'] - mu # 观察值与模型预测身高之间的差异
nll = -np.sum(-0.5 * np.log(2 * np.pi * sigma**2) - (residuals**2 / (2 * sigma**2))) # 高斯负对数似然
return nll
# 参数的初始猜测
initial_params = [178, 1, 5] # α、β和σ的起始猜测
# 最小化负对数似然以找到最佳拟合参数
result = minimize(negative_log_likelihood, initial_params, bounds=[(150, 200), (0, 5), (0.1, 20)])
# 提取拟合的参数
a_hat, b_hat, sigma_hat = result.x
print(f"Fitted α (Intercept): {a_hat}")
print(f"Fitted β (Slope): {b_hat}")
print(f"Fitted σ (Standard Deviation): {sigma_hat}")
# 绘制数据和拟合的回归线
plt.scatter(df['weight'], df['height'], label='Observed Data')
plt.plot(df['weight'], a_hat + b_hat * (df['weight'] - xbar), color='red', label=f'Fitted Line (α={a_hat:.2f}, β={b_hat:.2f})')
plt.xlabel('Weight')
plt.ylabel('Height')
plt.legend()
plt.title('Linear Model Fit')
plt.show()
"""
Fitted α (Intercept): 154.6443712012922
Fitted β (Slope): 0.9065651278307161
Fitted σ (Standard Deviation): 5.109386286044906
"""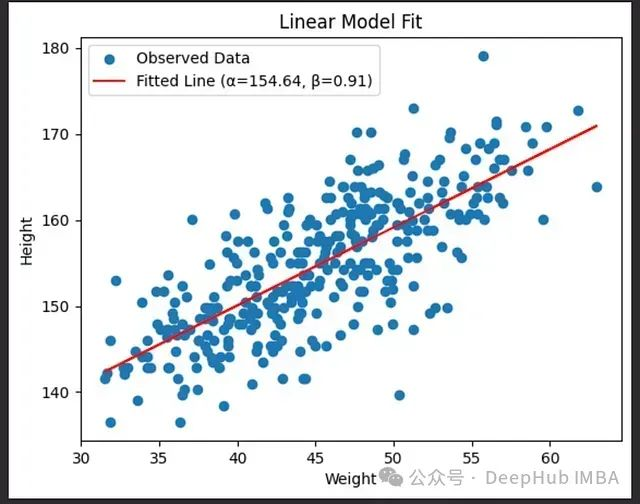
图21:线性模型拟合结果。
边际后验分布提供了在纳入观察数据后每个参数可能值的洞见。我们可以计算参数的标准误差和可信区间:
# 提取拟合的参数
a_hat, b_hat, sigma_hat = result.x
# 从Hessian矩阵计算参数的标准差(Hessian的逆给出方差)
hessian_inv = result.hess_inv.todense() if hasattr(result, 'hess_inv') else np.eye(3)
param_std = np.sqrt(np.diag(hessian_inv))
# 参数的摘要
param_means = [a_hat, b_hat, sigma_hat]
param_sds = param_std
lower_bounds = [a_hat - 1.645 * param_sds[0], b_hat - 1.645 * param_sds[1], sigma_hat - 1.645 * param_sds[2]]
upper_bounds = [a_hat + 1.645 * param_sds[0], b_hat + 1.645 * param_sds[1], sigma_hat + 1.645 * param_sds[2]]
# 打印摘要
print("Parameter estimates with 90% credible intervals:")
print(f"α (Intercept): mean = {a_hat:.2f}, std = {param_sds[0]:.2f}, 5.5% = {lower_bounds[0]:.2f}, 94.5% = {upper_bounds[0]:.2f}")
print(f"β (Slope): mean = {b_hat:.2f}, std = {param_sds[1]:.2f}, 5.5% = {lower_bounds[1]:.2f}, 94.5% = {upper_bounds[1]:.2f}")
print(f"σ (Std dev): mean = {sigma_hat:.2f}, std = {param_sds[2]:.2f}, 5.5% = {lower_bounds[2]:.2f}, 94.5% = {upper_bounds[2]:.2f}")
"""
Parameter estimates with 90% credible intervals:
α (Intercept): mean = 154.64, std = 0.28, 5.5% = 154.19, 94.5% = 155.10
β (Slope): mean = 0.91, std = 0.04, 5.5% = 0.84, 94.5% = 0.98
σ (Std dev): mean = 5.11, std = 0.19, 5.5% = 4.79, 94.5% = 5.43
"""这些结果表明,斜率(β)估计为0.91,意味着体重每增加1公斤,预期身高增加约0.91厘米。β的90%可信区间为[0.84, 0.98],表明我们对这个估计有相当高的确定性。我们还可以查看参数之间的协方差: cov_matrix = hessian_inv
print("\nCovariance matrix:")
print(cov_matrix)
"""
Covariance matrix:
[[ 7.63213604e-02 8.50653375e-06 -4.29656470e-04]
[ 8.50653375e-06 1.83876770e-03 -1.71020147e-06]
[-4.29656470e-04 -1.71020147e-06 3.79784425e-02]]
"""协方差矩阵显示参数(α、β、σ)之间的协变程度很小,这意味着每个参数的估计相对独立。
回顾我们的统计模型的第一行:
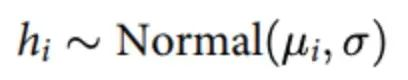
图22:统计模型公式。
这表明实际身高围绕预测平均值μi正态分布,标准差为σ。尽管模型对每个体重预测了一个平均身高μi,但实际身高会在这个预测周围变化,变化程度由σ控制。
为了生成预测,还需要考虑平均值μi的不确定性和围绕该平均值的可变性(由σ控制)。可以通过从正态分布中采样来模拟不同体重值的身高,这个正态分布的均值是预测的μi,标准差σ从后验分布中采样。
以下代码生成了一系列可能的身高,既包含了μi的不确定性,也包含了实际身高的可变性:
# 使用前一节的结果:
a_hat = 154 # 截距
b_hat = 0.9 # 斜率
sigma_hat = 5 # 标准差(sigma)
# 生成预测线(平均身高)
weight_seq = np.linspace(min(weight), max(weight), 100)
mu_mean = a_hat + b_hat * (weight_seq - np.mean(weight)) # 平均身高
# 模拟身高以生成预测区间
n_simulations = 1000
sim_heights = np.zeros((n_simulations, len(weight_seq)))
for i in range(n_simulations):
# 基于均值和sigma模拟身高
sim_heights[i, :] = norm.rvs(loc=mu_mean, scale=sigma_hat)
# 计算模拟身高的89%预测区间
lower_bound = np.percentile(sim_heights, 5.5, axis=0)
upper_bound = np.percentile(sim_heights, 94.5, axis=0)
# 绘制数据和预测区间
plt.scatter(df['weight'], df['height'], color='blue', alpha=0.5, label='Observed data')
plt.plot(weight_seq, mu_mean, color='black', label='Mean prediction')
# 89%预测区间的阴影区域
plt.fill_between(weight_seq, lower_bound, upper_bound, color='gray', alpha=0.4, label='89% Prediction Interval')
# 添加标签和图例
plt.xlabel('Weight')
plt.ylabel('Height')
plt.legend()
plt.title('89% Prediction Interval for Height based on Weight')
plt.show()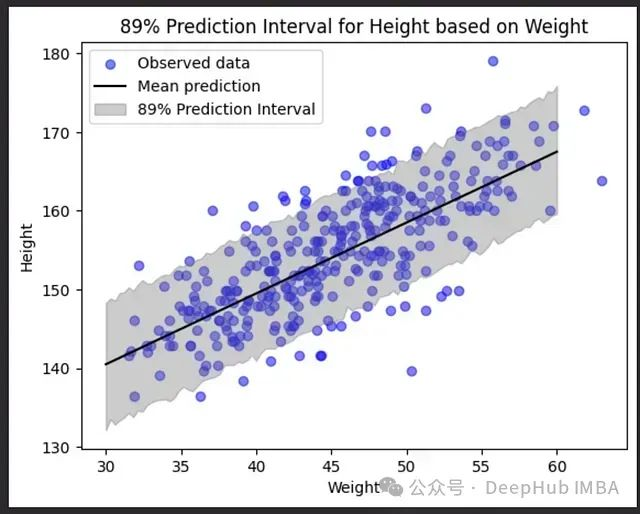
图23:基于体重的身高预测区间。
阴影区域显示了预测区间 — 这是给定一个人的体重,模型认为大多数实际身高将落入的范围,在这个例子中展示了一个89%预测区间,意味着阴影区域代表我们预期89%的身高会落入的范围。
多项式回归
在某些情况下,线性关系可能不足以准确描述变量之间的关系。多项式回归通过引入变量的幂(如平方或立方)来允许预测变量(如体重)和结果(如身高)之间的曲线关系。

图24:多项式回归示意图。
在多项式回归中,我们向模型添加额外的项,如β2x^2 (对于二次回归)或β3x^3(对于三次回归)。这些项引入了曲率,使模型能够更灵活地拟合数据。
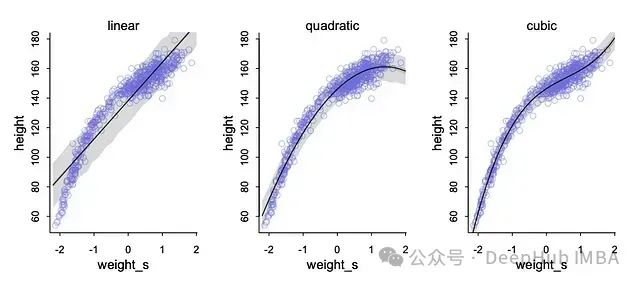
图25:多项式回归与线性回归比较。
样条
样条是一种更加灵活的方法,用于将曲线函数拟合到数据。不同于线性回归使用直线或多项式回归使用固定的曲线,样条将数据分成几个部分,并对每个部分拟合不同的曲线。这些曲线在称为结点的某些点上平滑地连接。
以下是一个使用样条拟合数据的示例,我们使用类似樱花开花温度随年份变化的数据:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.interpolate import BSpline
from sklearn.preprocessing import SplineTransformer
from sklearn.linear_model import LinearRegression
# 模拟类似樱花温度随年份变化的数据
np.random.seed(42)
years = np.linspace(839, 1980, 200) # 从839年到1980年
temp = 6 + np.sin((years - 800) / 100) + np.random.normal(0, 0.5, len(years)) # 一些"波动"的温度数据
# 使用Scipy的BSpline或sklearn的SplineTransformer拟合B样条
num_knots = 15
knots = np.quantile(years, np.linspace(0, 1, num_knots))
# 使用SplineTransformer创建基函数
spline = SplineTransformer(n_knots=num_knots, degree=3, include_bias=False)
year_transformed = spline.fit_transform(years.reshape(-1, 1))
# 对样条转换后的特征拟合线性回归
model = LinearRegression()
model.fit(year_transformed, temp)
# 使用拟合的模型创建预测
years_seq = np.linspace(min(years), max(years), 500).reshape(-1, 1)
year_transformed_seq = spline.transform(years_seq)
temp_pred = model.predict(year_transformed_seq)
# 绘图
plt.scatter(years, temp, color='blue', alpha=0.5, label='Observed Temp')
plt.plot(years_seq, temp_pred, color='red', label='Spline Fit')
plt.xlabel('Year')
plt.ylabel('Temperature')
plt.title('Spline Fit to Cherry Blossom Temperature Data')
plt.legend()
plt.show()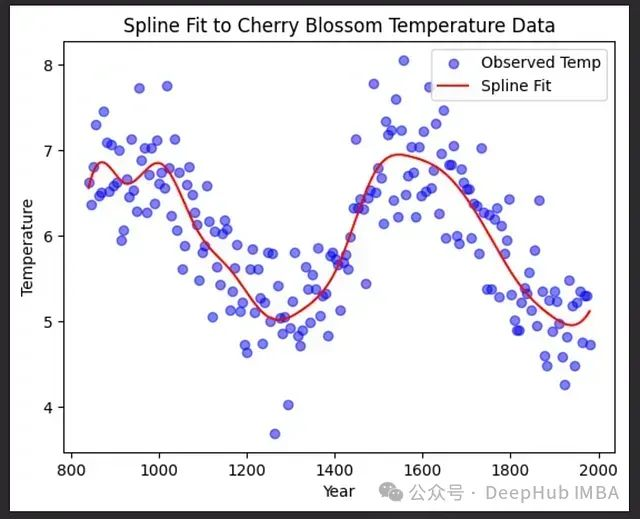
图26:使用样条拟合的樱花温度数据。
我们使用樱花开花日期的数据来说明样条的工作原理。这个数据集展示了从839年到1980年间温度的变化,这种关系相当复杂,不容易用简单的线性或多项式模型来捕捉。
样条方法的关键特点包括:
- 结点:我们在x轴(这里是年份)上放置特定的点,称为结点。这些结点将预测变量(年份)分成不同的区域。
- 基函数:每个区域都有一组基函数,这些函数控制该区域内曲线的形状。
- 局部性:在任何给定的时间点(如1306年),只有少数几个基函数会影响那一年的预测。这种局部性使得样条能够适应数据的局部变化。
- 平滑连接:尽管每个区域可能有不同的曲线形状,但这些曲线在结点处平滑地连接,确保整体函数的连续性。
- 灵活性:通过调整结点的数量和位置,以及基函数的阶数,我们可以控制拟合的灵活性。
样条方法相比于多项式回归有几个优势:
- 局部适应性:样条可以在数据的不同区域表现出不同的行为,而不会影响其他区域的拟合。
- 避免极端行为:高阶多项式在数据范围的边缘往往会表现出极端的行为,而样条通常能够避免这种问题。
- 计算效率:对于复杂的非线性关系,样条通常比高阶多项式更有计算效率。
在这个温度数据例子中,样条能够捕捉到温度随时间的复杂变化,包括长期趋势和短期波动。这种方法特别适用于需要在保持整体平滑性的同时捕捉局部细节的情况。
总结
贝叶斯线性回归提供了一个强大的框架,用于理解和量化变量之间的关系。通过引入先验分布和考虑参数的不确定性,这种方法不仅能给出点估计,还能提供完整的后验分布,从而更全面地描述我们的知识状态。
从简单的线性模型到更复杂的多项式回归和样条方法,我们看到了如何逐步增加模型的复杂性以捕捉数据中更细微的模式。每种方法都有其优势和适用场景:
- 线性回归适用于简单的线性关系,易于解释和实现。
- 多项式回归可以捕捉一些非线性关系,但在数据范围边缘可能表现不佳。
- 样条方法提供了更大的灵活性,能够适应复杂的非线性关系,同时保持局部的平滑性。
在实际应用中,选择合适的模型通常需要平衡模型复杂性、数据拟合程度和解释性。贝叶斯方法的一个关键优势是能够通过模型比较(如使用贝叶斯因子)来形式化这种权衡。
此外贝叶斯方法还允许我们将先验知识纳入模型,这在数据有限或存在强烈的领域知识时特别有用。通过合理设置先验分布,可以改善模型的预测性能特别是在小样本情况下。
尽管本文主要关注了连续变量的回归问题,但贝叶斯方法的应用范围远不止于此。类似的原理可以扩展到分类问题、时间序列分析、多层次模型等多个领域。随着计算能力的提升和算法的进步,贝叶斯方法在数据科学和机器学习中的应用前景将越来越广阔。
