
盘点「量化交易全流程」中的30个大坑!
这篇文章的作者是一之目,10年前他发表过一篇文章《量化交易的十大陷阱》,这篇文章被各路媒体广为转载,相信不少朋友也阅读过。至今虽然已经过去了十年,量化交易领域也衍生出了更多的方法论,但其中内容在现在看来也还是很有价值,文中提到的很多坑在当下仍然是很多初学者易犯的错误。
经过十年的积累和沉淀,一之目已经成长为一位全栈Quant大佬,从中低频因子到高频策略、算法交易、演化算法、AI模型一路到高性能IT底层,整个量化技能树已经几乎点满,业绩曲线也是稳如老🐶,目前他也在头部量化私募负责算法交易。十年后,Puppy有幸邀请到了他再来讨论这个话题~
这次我们就以整个量化策略开发的流程为思路,来重新理一理Quant们从新手村出发成长为老司机的过程中必踩的坑。全文接近6000字,Puppy对文章做了排版和配图。
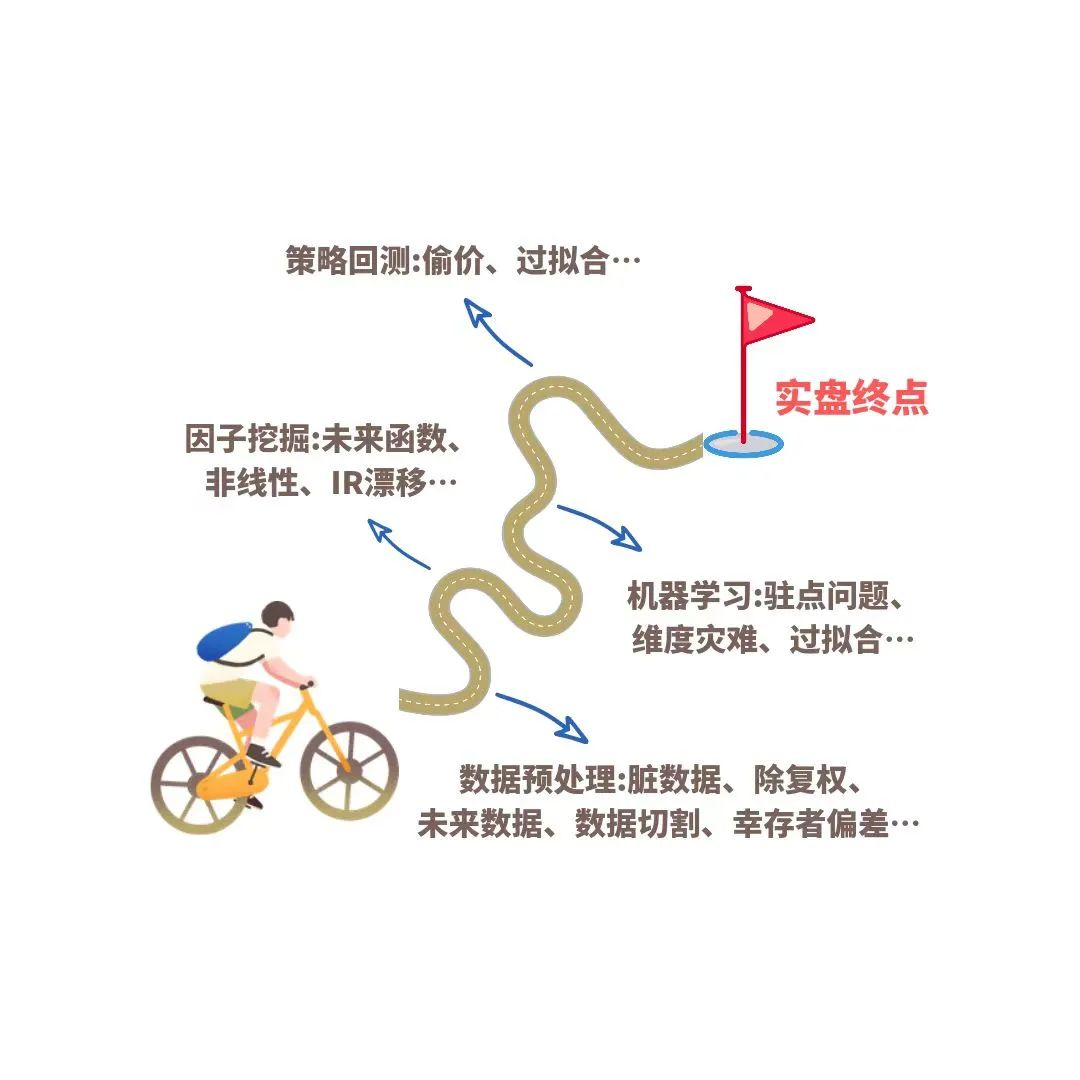
我们先从量化交易第一步–数据开始说起。01
数据收集
1、差错
凡是数据都有可能有差错,拿到数据以后一定要先仔细排查一遍,这是最基础,但很多新手Quant往往会忽略的一步。
即使是官方的数据源,也可能会出现包括价格错误,时间错位,乱序,重复,缺失,中断,乱码,列错位,代码错位等问题,非官方数据源的问题只会更多。不做处理的话,这些数据被代入后续的计算,一定会导出错误的结果,而且这些细小的差错往往是在很靠后的步骤才会察觉。正所谓,一步错,步步错。而如果是在实盘的情况下,一个差错数据可能就是灾难性的影响。
2、无效值
数据无效不一定是差错,可能只是没有成交,或者涨跌停,停牌等等问题。对于这种无效值,不一样的处理会得出不一样的结果,这结果可能是天差地别的,也可能影响到你后续所有的结果。
你一定要仔细思考,什么数据应该填0,什么数据向前填充,什么数据不要填充。打个比方说,如果盘中的空值数据使用了向前填充,它就变成了未来数据;而如果价格纲的数据填了0,就会让均值计算出现错误。这种问题在极端情况下会出现,也会影响你的策略和模型,得出不正常的结果。
3、失真
在一些极端情况下,你收到的行情可能还在跳动,但你的报单可能会被屏蔽,不会成交。或者是成交了,但是回头被交易所判定为无效交易,全部取消。或者是行情就直接不跳了,你盘后收的历史行情是后补的。你的策略在这种极端情况下不一定能赚到回测中“赚”到的钱,而回测中亏的钱大概率会亏出去。
前几年币圈有过所谓拔网线的先例,或者更多的直接回滚交易,退市换币,更早的时候不要说币圈,连国内股市期市都出现过类似的问题。有亲身经历的朋友,一定知道我说的是哪些事。02
数据处理
1、除复权
也许你想不到,但这确实是可能会美化你资金曲线的第一个大坑。前复权、后复权、等比复权、等差复权,他们各自都有适用的场景,也有自身的限制。
比如,我们一般炒股时都会看前复权,因为它最新价是准确的,但它是个未来数据,前复权后历史价格会很低,策略里很可能会提炼出一个“买入超低价股”的条件,坐享收益。
又比如后复权,虽然历史价格不改变了,但是盘口和最新价都是不准确的,计算手续费、仓位的时候都有偏差。而再比如等差复权,它历史价格会复权出负数,等比复权又会破坏跳点关系等等。
2、未来数据
在对齐一些另类数据的时候,要想一想在你贴时间戳的那个时刻,这些数据来到了吗?确定了吗?正因为如此,才有一种叫PIT(point in time)数据,它是指在那个时间点真实看到的数据,其后也不会发生改变,它是一个时间序列。
有些财报数据会在发布以后,又称数据有错误,并公告修正,那么他公告后的数据在公告之前就是未来数据。另外一些数据有它应有的延迟,把这些延迟抹去忽略了,它也是未来数据。而未来数据就像未来函数一样,杀伤力巨大。
3、数据切割泄露
样本内外数据能做shuffle, stride吗?k fold真的fold了吗?AI工程师转行量化容易出这样的问题,但在亏钱之前也许没有人会指出你这样做是错的。
4、幸存者偏差
我们看到的只是活下来的股票,而那些已经消失在历史长河中的、已经退市了的股票,你可能连回测数据都找不到,事后的回测自然而然就剔除了,但当时这些股票是确实存在的,而且参与到了你的交易决策之中。
5、离散交易连续处理
有时候我们会以一些假设来简化逻辑进行回测,但实际上某些假设确实会很影响绩效。
简单的来说,内盘股票是T+1一手一手买的,你不能1毛1毛这样买,买入部分当天也不能卖,简化这些逻辑可能会磨平资金曲线的跳动。另外现在有些指数的编制规则也一定程度上存在着这种连续处理的特性,比如它会实时连续的调整权重,但我们不能连续以零股调整仓位,所以相对而言更难复制。03
因子挖掘
1、未来函数
未来函数是个天坑,大家都知道,它指的是计算历史信号时引用了未来信息。但是你可能不知道的是,你调用的一些函数可能本身就是未来函数,这在信号学里尤其多,比如ZigZag、傅里叶变换、缠论波浪理论的数浪。这种对未来数据的引用多见却又隐蔽,以至于很多量化老手也不能幸免。
加入未来函数会对回测的结果产生巨大影响,因为量化模型的学习效率非常强,所以哪怕只有一点未来的东西进来,都会造成夸张的结果。
那我们怎么识别是不是误入了未来函数呢?记住这条判断金标准:
「在新的数据进来了后,历史输出会不会发生变化?」
2、换手率
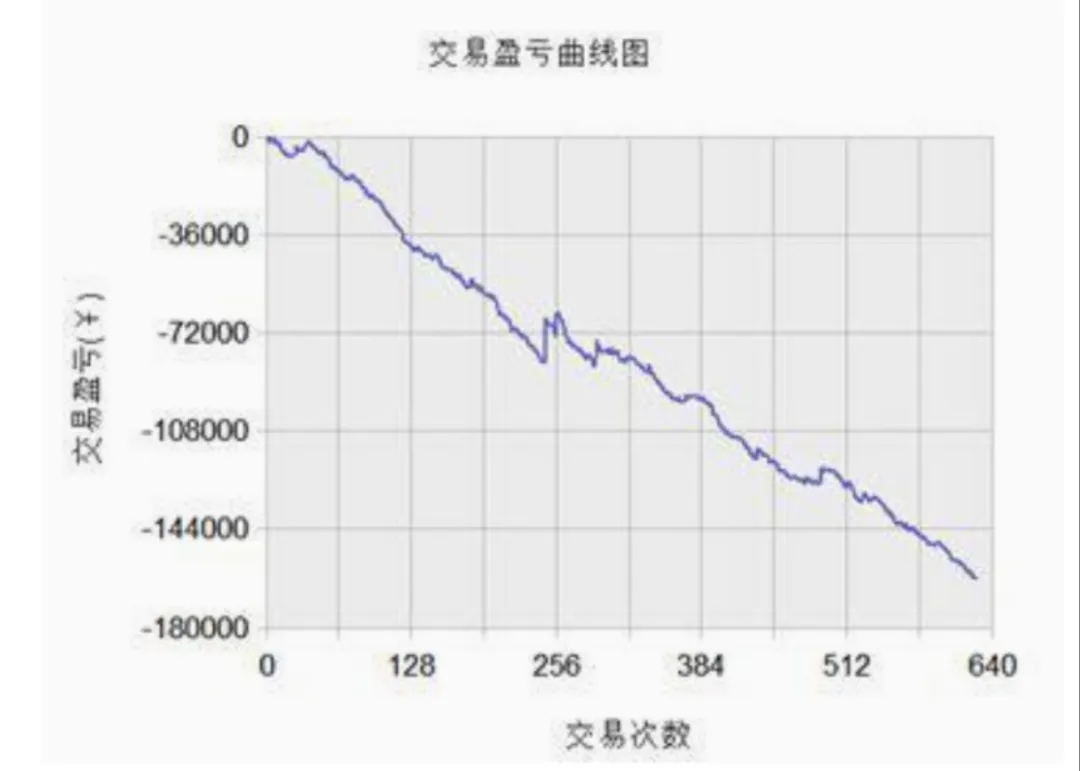
高频因子天然存在着很强的解释性,但没有用,因为它有着更高的换手率(意味着更频繁的调仓,导致比较高的手续费)。
当你看到一条无限笔直的因子收益曲线,先别太开心,上费算一下?你按照它去做很可能根本打不回成本,一上费就血亏,全交手续费了。所以笔直的因子回测收益曲线不一定有价值,笔直的实盘资金曲线才有价值。
上费前的盈亏曲线:

上费后的盈亏曲线:
3、同轴共线性
因子是越多越好吗?其实并不是。从同一个逻辑出发挖出的因子,如果不做筛选,可能会相关性非常高。同质化的因子代入模型,就会引发同轴共线性,矩阵都不满秩,再上高阶,一定无解。
4、非线性
因子的阶数怎么定,高阶确实缺乏可解释性,但并非所有的因子都是线性的,非线性处理放进因子是个比较取巧的骚操作,但也不是不行,关键是看你怎么把握这个度。骚到一定程度直接在因子层面就把收益率给拟合了,那纯属作弊,并不是真的牛逼。
5、IR漂移
IR反映了因子解释性的稳定性,可以理解为因子的回撤。有些因子看上去美好,但却是平时正负飘,偶尔极值高。04
模型组合
1、样本
有一种说法是,你所做的回测所有的样本外,其实都是样本内。因为它必然会参与你对模型和超参数的选择,只要你用过,就是样本内。
2、数据量
机器学习需要巨大的数据量来覆盖所有情况,然而实际情况是,金融数据的信噪比低,维度大,所以无论多大的数据量都还是太小。
3、过拟合
模型组合层面最怕过拟合,但过拟合只是一种表现,你在拟合过程中并不知道它是过拟合还是欠拟合,只能通过一些技巧来辅助判断,比如这张经典的测试集验证集损失曲线:
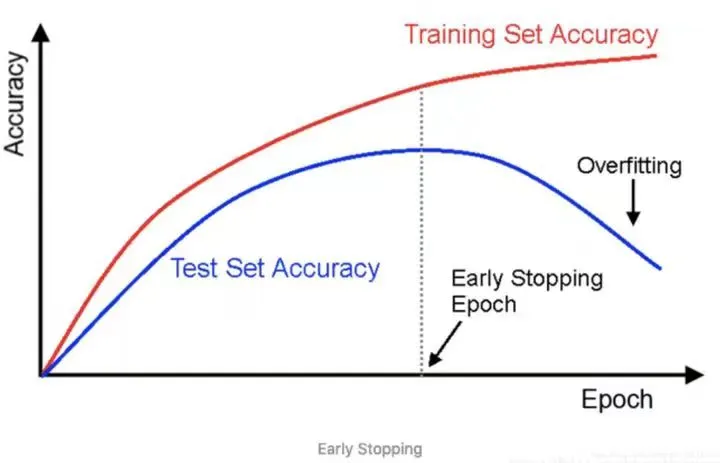
然而,这种平滑的曲线在金融数据集上可能并不存在,一旦存在波折以后如何确定拟合精度,就变成更多艺术而非科学。
4、维度灾难
维度灾难是在特征数量层面上的过拟合,当特征维度足够大以后,总有那么一组特征组合能够准确分离出标签,然而这种组合代表的只是噪声,根本没有泛化性。
想象在一个超立方体的特征空间中,存在一个超球体,包裹了所有正例样本。在维度越来越大的过程中,超球体的表面积会变得越来越大,而体积却会越来越小。
5、驻点问题
深度学习通过链式求导法则进行反向传播来实现梯度下降,树模型也有梯度提升过程。只要求梯度,就有可能遇到驻点。当你亲手遇到梯度消失和梯度爆炸的问题时,也许就不是轻描淡写的换个激活函数那么简单。05
策略逻辑
1、偷价
如果我们买入是按照卖一价下单入场的,而策略回测又是以收盘价来计算,那么如果收盘价正好在买一价,我们就少算了一跳成本,这是存在偷价的。
不要小看这些点,积累的交易足够多以后,它虚增的利润足以把回测资金曲线粉饰得非常漂亮。回到一些回测的假设上来,如果我们对滑点的假设过于乐观,也有可能会陷入偷价的问题。
2、过度优化
过度优化主要是人为的让策略陷入一个参数孤岛,任何一个变量发生细微变化都会使策略绩效显著下降,这种参数在未来是显然不可持续的。过度优化和过拟合一样,只不过这步我们更加可控,也更直观。
还有一点我们需要警惕的是,优化的操作会带你向它固有的坑中引导,可能你原本并没有的一些其他坑,在优化之后却产生了。
另一方面,过度优化在商用策略上屡见不鲜,多少有点有意为之的感觉,是卖策略的“神器”。我见过有一种让人啼笑皆非的过度优化方式,是在代码里用if else标明亏损的那一天不交易……
为了让曲线好看,策略更好卖,就是这么简单粗暴。所以事实证明没看到源码和实盘之前,我们都要抱着怀疑的态度。
3、普适性问题
对于一些不满意的交易,我们一定会进行回溯检查,这是策略开发中的一个必要流程,但它也有一个度。比如针对一段特定的行情进行参数优化,或者叠加了很多条件,这类条件又只针对一些特定行情或特定品种,那么通过这种手法得到的一条完美的资金曲线,就没有普适性。06
策略回测
1、逻辑顺序
当你排除了上面的万难,终于来到最终策略回测的阶段,可是对不起,还有很多坑等着你,而且就最终影响来说,这部分的坑影响可能是最大的。
首先,很多策略是直接在bar上测试的,bar有一个假定的触发顺序,但这并不一定是真实顺序。
比如盘中有可能是先触发最高价,再触发最低价,还有可能先触发一个不到最高价的价格,然后触发最低价,最后又触发最高价。那么策略有可能会先触发止盈,回测又标记了一个更高的止盈,或者已经触发了止损,回测却标记了止盈。是先触发买卖,还是先触发止损止盈,这里也会造成很大的差别。
2、成交机制
成交机制中最常见的一个坑,是利用盘中价格作为成交价,这个常见于突破策略。但盘中很多时候只是一瞬间的价格,这个瞬间的盘口可能不是对盘价让你撮合这么简单。
另外一种,在回测中用「收盘价」买入也是不合实际的,因为「收盘价」一般是交易不到的,只能以下一个k线的「开盘价」成交,但是如果下一个k线发生了跳空,这个跳空的成本也是要被考虑在内的。
3、强制撮合
强制撮合是指回测程序让你买进或卖出了实际不可能成交的份额,典型的比如涨跌停。涨停只能卖,跌停只能买,如果错过了涨停前的机会,那后面十几个连板是跟你没关系的,强制撮合就会虚增你的利润。
同样跌停如果没卖成,后面连续跌停缩水50%以上也是有可能的,可稍微一点改动,强制撮合可能就帮你绩效曲线“避”了一个大坑。
4、市场容量
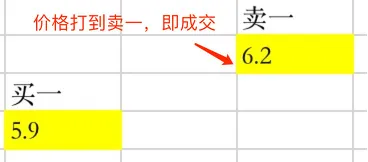
一种常见的撮合机制是「见价成交」机制,就是说如果你挂买单的价格和当前卖一相等,委托单就视为成交。而实际情况还需要考虑订单优先和订单厚度,对手盘口可能在你下单的一瞬间撤单了或者被人抢去了,也可能你想买很多但对盘口只有很少。遇到这样的问题,你只能推迟这个信号点,或者加价委托。
5、滑点
盘口滑点是你真实成交价格与信号点的差距,这在一些情况下可能会相当大,尤其在高频策略回测上,如果不考虑滑点,很可能会将一个稳定亏损的策略错误估计为稳定盈利。
加价打对手价的时候,也会涉及到滑点的估计,这个在回测的时候取决于策略的特性和你的乐观程度,自由度相当大。而实盘可不是这样,实盘会存在逆向选择,凡是你没成交的单子,都会是本来赚钱的单子;而亏钱的单子,则一定会被撮合掉。
6、商业平台
很多朋友会选择在商业平台上做二次开发,以节约开发时间,或者专注在策略逻辑上。但是商业平台很多逻辑是写死的,一方面我们没办法做太多定制化的东西,会限制一些功能。
比如数据也许不能导入导出,或者不能引用一些其他数据,又或者一些特定的函数没法实现。另一方面我们对它内在逻辑并不会十分了解,这可能会产生一些让你亏钱的坑,比如数据差错、串流,或者一个不起眼的设置让你没有及时下单或者反复下单等等。
更多的可能是在回测的时候一些细节,美化了你的策略在这个平台上回测的表现。比如你在某些盘口流动性不好的品种上做回测,它可能给你重复撮合,也就是说t时刻你用对手盘搓掉的自己的买单,t+1时刻这个对手盘还在,又给你撮合了,极端情况下,你的单子能无限以这个价位全部撮合完。

顺便提一句,如果单量比较大,现实中你太不可能在一笔订单中以同一个价格大量成交,这就是需要算法交易发威的地方。07
实盘阶段
1、延迟
当你再次排除万难,带着你稳定盈利的策略来到实盘。可当你遇到这两个问题,还是会让你稳定盈利的策略变成稳定亏损。
大坑其一,就是延迟。凡是网络传输,就不可能没有延迟,你可以不会测试到,也无法估计延迟对你策略的影响,但它还是会潜移默化地影响着你的绩效。延迟可能发生在行情端,也可能发生在委托端,总之它延长了你的tick-to-trade的时间,让你的一些单子无法成交。延迟是高频交易的天敌,它可能会直接废掉一个优秀的高频策略。
2、断流
在互联网环境下,网络会有抖动,除了长时间的网络中断,你有时候还会观察到1s内没有tick,下一秒又来了好几个,这个也是断流。小于轮询间隔的瞬时断流是不会被系统检测到的,但它会影响你的策略。
面对这样的问题,是不是还有更好的接入方案?你的策略里做好容错机制了吗?一旦断流、缺失、延迟,你的策略能够应对吗?好在如果解决了这些问题,断流相对而言还是好避免的。
3、成交率
最后一个想讲的坑,是成交率。成交率是回测预期能成交的订单,在实盘中成交的比例,反过来就是撤单率。成交率也是一种表现,因为影响订单能否成交的因素太多了,价格、量、时间三者都可能产生意外不成交。
同样由于逆向选择的问题,亏钱的都成了,赚钱的都飞了。对于一些高频策略,实盘真实的成交率可能让你大跌眼镜,直接让你一套美好的策略无法付诸实践。
要科学地定量策略来解决这些问题,就需要一套完整的算法逻辑来维护整个订单的生命周期,很多个人quant在这个问题上是不会有过多思考的。 08
总结
近几年,在机器学习被引入量化交易之后,越来越多的模型被提出和移植进金融数据。然而坑并没有被填上,反而是更多了!
一方面机器学习上会遇到的坑,例如数据清洗、正则化标准化、同轴共线性等等,在金融领域一样会遇到,需要更多的经验才能处理。
另外一方面,由于金融市场低信噪比、高有效的特性,配上机器学习强大的拟合能力,产生出了更大的坑。二者一结合,往往就是“一顿操作猛如虎,结局是个二百五”。
不知道大家有没有这样的经历,好不容易写出来的策略,测出来资金曲线非常满意,但往往经过一段时间的仔细排查,甚至是上了实盘发生亏损以后,再回过头来察觉到里面存在着重大bug,修完以后发现它显现的真身其实是一份无比糟糕的业绩。
这种情况非常令人沮丧,可又如此常见,以至于我们现在看到一条完美的资金曲线,如果不是实盘业绩,首先要抱着怀疑的态度去证伪,因为有太多的坑会让你描绘出一条特别好看但却虚假的资金曲线。
