
时间序列分析的Python库和适用场景
时间序列分析在各个领域都有广泛应用,从金融预测到环境监测,再到工业过程控制。Python作为一门强大的数据科学语言,提供了丰富的库来支持时间序列分析。将通过一张图和简单的说明,帮助大家快速了解这些库的主要功能和适用场景。
1. 预测
搜索一个函数,该函数预测预测时间线的值接近那些时刻的实际系列值。
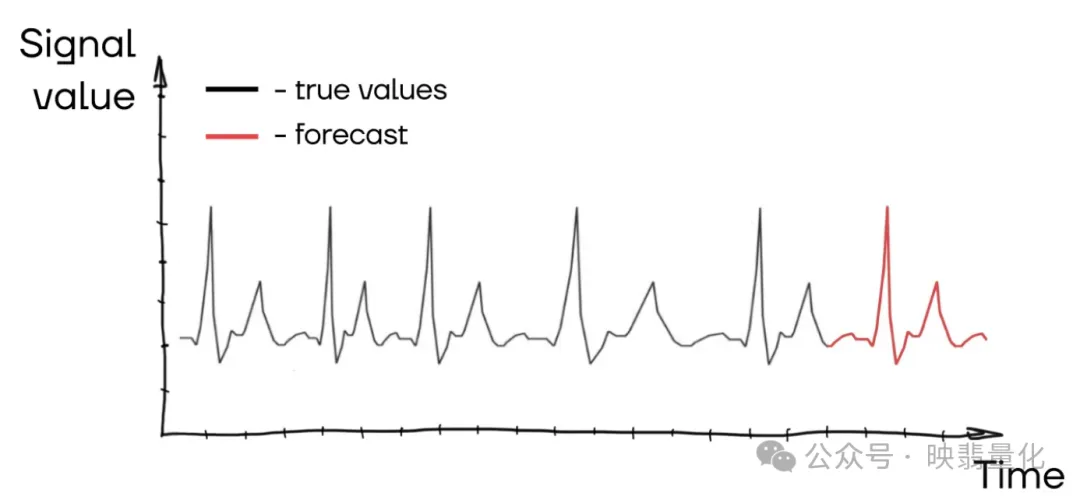

- Prophet: Facebook开源的库,擅长处理具有强季节性和趋势的时间序列数据。
- statsmodels: 提供了经典的时间序列模型,如ARIMA、SARIMA等。
- SKTIME: 一个相对较新的库,提供了全面的时间序列建模和预测功能。
- Darts, Kats, MERLION: 这几个库提供了更多样化的模型和算法,可以满足不同的预测需求。
2. 分类
根据时间序列的特点,将时间序列分配给预定义的类别或类之一。


- SKTIME, tslearn, Deep Learning for Time Series Classification: 这几个库专注于将时间序列数据分类,用于识别不同类型的事件或模式。
- pyts, ETNA: 提供了更灵活的时间序列分类方法。
3. 聚类
将不同时间序列的原始集合分为组,以便组内时间序列特征之间的差异最小,组之间的差异最大。与分类不同,没有预定义的类。
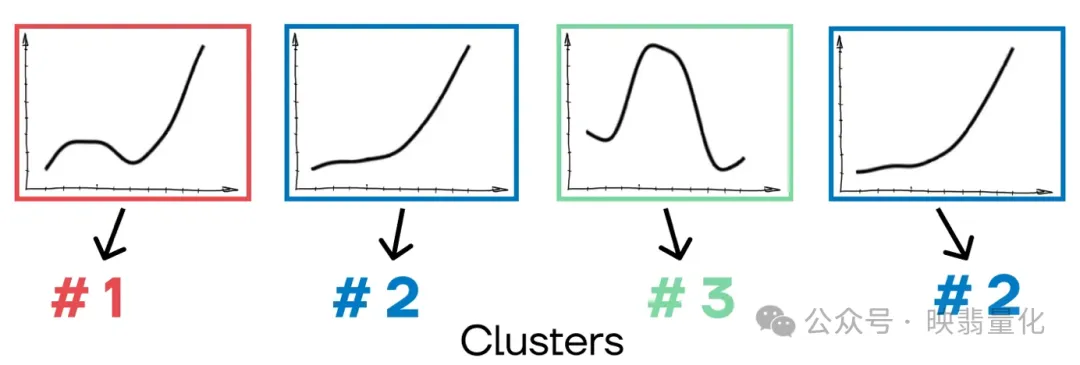

- SKTIME, tslearn: 这两个库提供了时间序列聚类算法,用于将相似的时间序列分组。
4. 模式检测
在更长的时间序列中搜索特定模式(特定序列)。这项任务与聚类和分类非常相似。


- stumpy: 可以帮助你检测时间序列中的突变点、季节性模式等。
5. 聚合与特征提取
从时间序列中提取各种统计特征和参数。当我们需要将时间序列转换为经典的表格数据格式时,会进行汇总,其中每行代表一个独立的数据点。
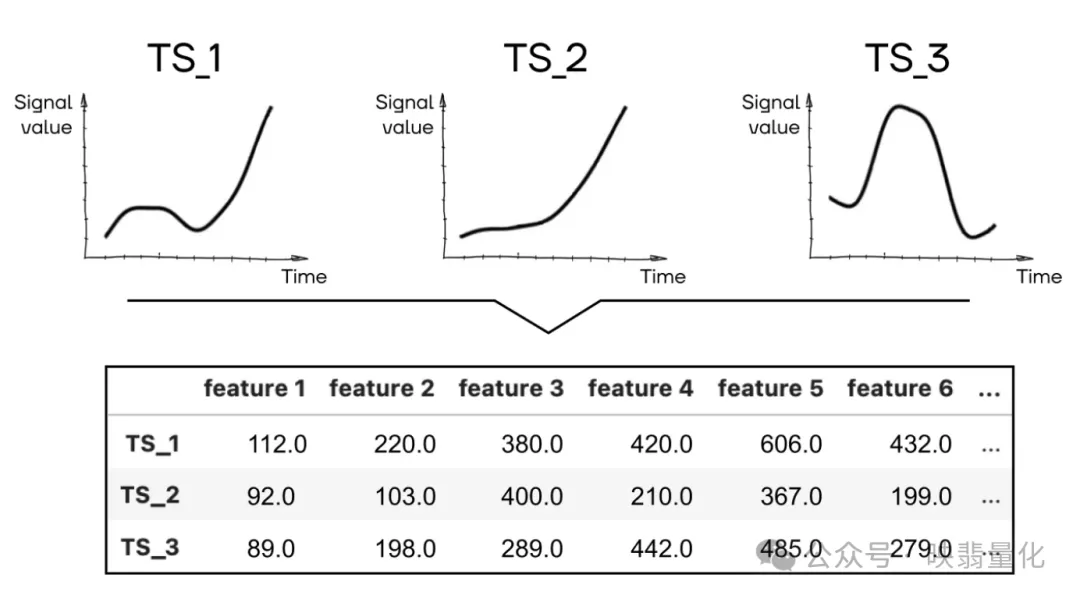

- tsfresh, tsfel等: 这些库可以从原始时间序列中提取出有意义的特征,为后续的建模提供支持。
6. 切点检测
检测过程变化的特定点(变化点),例如,集体异常开始(或结束)的地方


7. 异常检测
找到与一般分布不对应的单个点(异常值),或将每个点分配给正常或异常类。可以表述为分类或聚类问题。

- PyOD, TODS, ETNA, Luminiare: 这些库可以帮助你识别时间序列中的异常值。
8. 增强和数据生成
增强涉及通过人为创建或合成新数据来扩展数据集,以覆盖未探索的输入空间。
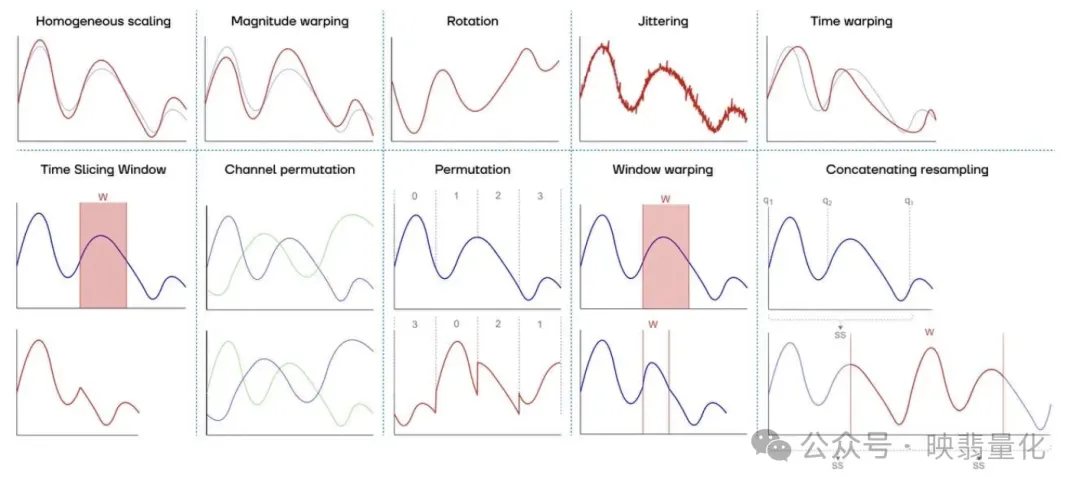

- tsai, RGAN, tsaug, TimeSynth: 这些库可以生成新的时间序列数据,用于扩充数据集或进行模型训练。
如何选择合适的库?
选择合适的库取决于具体需求:
- 数据特点: 数据是否具有季节性、趋势性?是否有异常值?
- 预测目标: 是想进行点预测还是区间预测?
- 模型复杂度: 希望使用简单的模型还是复杂的深度学习模型?
- 可解释性: 是否需要对模型的预测结果进行解释?
实战示例
假设有一组股票价格数据,想要预测未来的价格走势。可以按照以下步骤进行:
- 数据预处理: 使用Pandas读取数据,并进行清洗和转换。
- 特征工程: 使用tsfresh等库提取特征。
- 模型选择: 根据数据特点选择合适的模型,比如Prophet或LSTM。
- 模型训练: 使用训练数据训练模型。
- 模型评估: 使用测试数据评估模型的性能。
- 模型预测: 使用训练好的模型进行预测。
总结
Python提供了丰富的库来支持时间序列分析,选择合适的库可以大大提高工作效率。在实际应用中,可以结合多个库来构建更复杂的模型。
