
统计套利和贝叶斯优化实现配对交易,中性策略,代码复制可用
什么是配对交易配对交易是指八十年代中期华尔街著名投行Morgan Stanley的数据交易员Nunzio Tartaglia成立的一个数据分析团队提出的一种市场中性投资策略,其成员主要是物理学家、数学家、以及计算机学家。Ganapathy Vidyamurthy在《Pairs Trading: Quantitative Methods and Analysis》一书中定义配对交易为两种类型:一类是基于统计套利的配对交易;一类是基于风险套利的配对交易。基于统计套利的配对交易策略是一种市场中性策略,具体的说,是指从市场上找出历史股价走势相近的股票进行配对,当配对的股票价格差(Soreads)偏离历史均值时,则做空股价较高的股票同时买进股价较低的股票,等待他们回归到长期均衡关系,由此赚取两股票价格收敛的报酬。配对交易策略的基本原理是基于两个相关性较高的股票或者其他证券,如果在未来时期保持着良好的相关性,一旦两者之间出现了背离的走势,且这种背离在未来是会得到纠正的,那么就可能产生套利的机会。对于配对交易的实践而言,如果两个相关性较高的股票或者其他证券之间出现背离,就应该买进表现相对较差的,卖出表现相对较好的。当未来两者之间的背离得到纠正,那么可以进行相反的平仓操作来获取利润。由于配对交易利用配对间的短期错误定价,通过持有相对低估,卖空相对高估,因此其本质上是一个反转投资策略,其核心是学术文献中的股票价格均值回复。尽管配对交易策略非常简单、但却被广泛应用,其之所以能被广泛应用的主要原因是:首先,配对交易的收益与市场相独立,即市场中性,也就是说它与市场的上涨或者下跌无关;其次,其收益的波动性相对较小;第三,其收益相对稳定。使用统计套利技术和贝叶斯优化实现复杂的配对交易策略分析框架:
- 数据收集和预处理
- 下载50家主要公司的历史股票数据,使用yfinance
- 清理和调整数据以供分析
2.配对选择
- 协整测试
- 相关性分析
- 对平稳性进行增强的Dickey-Fuller(ADF)测试
- 排名并选择最佳交易配对
3.配对交易策略开发
- 计算关键参数:Kappa和半衰期
- 使用Backtrader实现PairTradingStrategy类
- 定义进入和退出逻辑
- 实施风险管理技术
4.回测引擎
- 开发自定义BacktestEngine类
- 模拟历史数据的交易
- 计算全面的绩效指标
5.贝叶斯优化
- 定义用于优化的参数空间
- 创建一个基于夏普比率的目标函数
- 实施并运行优化过程,以找到最佳策略参数
6.结果分析
- 可视化收益曲线
- 生成和分析交易表
- 计算和解释关键绩效指标
7.未来的改进
- 建议对战略进行潜在的增强
- 讨论需要进一步研究和开发的领域
8.结论
- 讨论统计套利在现代市场中的潜力
- 提供关于定量交易策略未来的想法
该项目结合了先进的统计方法和机器学习优化技术在开发强大的配对交易系统中的应用。通过遵循这种结构化方法,我们的目标是制定一种策略,能够以系统化和数据驱动的方式识别并利用市场效率低下的情况。使用的关键技术和库包括Python、Jupyter Notebook、yfinance、pandas、numpy、statsmodels、Backtrader、scikit-optimize(skopt)和matplotlib。
1.数据收集和预处理
任何强大的交易策略的基础都在于高质量、准备充分的数据。在本节中,我们将讨论我们收集和预处理我们配对交易策略所需的历史股票数据的方法。
A.选择股票池
实例里选择了最近总市值最高的25只和总市值最低的25只(剔除ST)沪深股票池。虽然A股不能做空,但是可以融券,实例里的股票未考虑是否可以融券。后续可以拓展到不同类别的品种,比如可转债、股指期货、商品期货、期权等可以做空的品种上。用部分国外的商品期货测试了一下,胜率不错!!
当然可以扩展为其他不同行业和不同类别之间的潜在配对。
B.使用yfinance下载历史数据
为了获取历史股票数据,我们使用yfinance库,可以从雅虎财经下载数据。以下是我们实现数据下载过程的方法:
import yfinance as yfimport osfrom datetime import datetime# List of 50 stock tickers#list_tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'TSLA', 'BRK-A', 'V', 'JPM', 'JNJ', 'WMT', 'UNH', 'MA', 'PG', 'NVDA', 'HD', 'DIS', 'PYPL', 'BAC', 'CMCSA', 'ADBE', 'XOM', 'INTC', 'VZ', 'NFLX', 'T', 'CRM', 'ABT', 'CSCO', 'PEP', 'PFE', 'KO', 'MRK', 'NKE', 'CVX', 'WFC', 'ORCL', 'MCD', 'COST', 'ABBV', 'MDT', 'TMO', 'ACN', 'HON', 'UNP', 'IBM', 'UPS', 'LIN', 'LLY', 'AMT']list_tickers = ['600941.ss', '601398.ss', '601939.ss', '600519.ss', '601288.ss', '601857.ss', '601988.ss', '600938.ss','601628.ss', '600036.ss', '300750.sz', '601088.ss', '600028.ss', '601318.ss', '600900.ss', '002594.sz','601728.ss', '601328.ss', '601658.ss', '000858.sz', '601138.ss', '000333.sz', '601899.ss', '688981.ss','601166.ss', '688021.ss', '688701.ss', '688096.ss', '002629.sz', '688217.ss', '000982.sz', '688565.ss','688178.ss', '688004.ss', '603021.ss', '600539.ss', '688659.ss', '688679.ss', '603272.ss', '688215.ss','002193.sz', '600455.ss', '600768.ss', '688681.ss', '300478.sz', '688067.ss', '000668.sz', '300929.sz','603316.ss', '688296.ss']# Set start and end timesstart_time = '2021-01-01'end_time = '2024-07-29'# Create a folder to save data if it doesn't existfolder_name = 'stock_data'if not os.path.exists(folder_name):os.makedirs(folder_name)# Function to download and save data for a stockdef download_and_save_stock_data(ticker):try:# Download datadata = yf.download(ticker, start=start_time, end=end_time)# Create file namefile_name = os.path.join(folder_name, f"{ticker}.csv")# Save data to CSV filedata.to_csv(file_name)print(f"Downloaded and saved data for {ticker}")except Exception as e:print(f"Error downloading data for {ticker}: {str(e)}")# Download and save data for all stocksfor ticker in list_tickers:download_and_save_stock_data(ticker)print("Completed downloading data for all stocks.")
下载每只股票从2021年1月1日至2024年7月29日的每日数据,为我们提供了三年多的历史数据。文末提供全部代码,省去一段一段的复制麻烦。
2.配对选择
在配对交易里,选择正确的股票配对策略的成功至关重要。我们的方法结合了几种统计方法,以识别具有最高盈利平均回归交易潜力的配对。
A.协整的介绍及其重要性
协整是我们配对选择过程中的一个基本概念。如果两个时间序列共享一个长期均衡关系,即使它们在短期内可能偏离这一均衡,那么它们就被认为是协整的。对于配对交易来说,协整意味着两只股票之间的价差倾向于随时间回归到均值,从而提供了交易机会。
B.协整测试
我们使用Engle-Granger两步法来测试协整性。这在我们的analyze_pair函数中实现:
from statsmodels.tsa.stattools import cointdef analyze_pair(stock1, stock2):# ... other code ...# Check Cointegrationscore, pvalue, _ = coint(stock1['Close'], stock2['Close'])# ... other code ...
来自statsmodels的coint函数执行共整合测试,返回一个p值,我们用它来评估共整合关系的强度。
C.相关性分析及其作用
虽然协整抓住了长期关系,但相关性有助于我们了解股价的短期共同移动。我们计算势对之间的相关系数:
def analyze_pair(stock1, stock2):# ... other code ...# Calculate Correlationcorrelation = stock1['Close'].corr(stock2['Close'])# ... other code ...
高度相关的对可能表明关系更强,但我们也认为较低的相关性可以提供更多的交易机会。
D.增强的Dickey-Fuller(ADF)平稳性测试
ADF测试帮助我们确定两种股票之间的利差是否是静止的,这对平均回归策略至关重要:
from statsmodels.tsa.stattools import adfullerdef analyze_pair(stock1, stock2):# ... other code ...# Augmented Dickey-Fuller Test on log spreadadf_result = adfuller(log_spread)# ... other code ...
固定价差表明,随着时间的推移,这两种股票之间的差异往往会恢复到平均值,这非常适合我们的策略。
E.排名和选择最佳配对
使用以下方法分析股票池中所有可能的配对:
def analyze_all_pairs(tickers, data_folder='stock_data'):results = []for ticker1, ticker2 in combinations(tickers, 2):try:stock1 = load_stock_data(ticker1, data_folder)stock2 = load_stock_data(ticker2, data_folder)# Ensure both stocks have the same date rangecommon_dates = stock1.index.intersection(stock2.index)stock1 = stock1.loc[common_dates]stock2 = stock2.loc[common_dates]result = analyze_pair(stock1, stock2)results.append({'pair': f'{ticker1}-{ticker2}','cointegration_pvalue': result['cointegration_pvalue'],'correlation': result['correlation'],'adf_pvalue': result['adf_pvalue'],'mean_zscore': result['z_score'].mean(),'std_zscore': result['z_score'].std()})except Exception as e:print(f"Error analyzing pair {ticker1}-{ticker2}: {str(e)}")return pd.DataFrame(results)def filter_suitable_pairs(df_results, cointegration_threshold=0.05, adf_threshold=0.05):return df_results[(df_results['cointegration_pvalue'] < cointegration_threshold) &(df_results['adf_pvalue'] < adf_threshold)].sort_values('correlation', ascending=False)def find_best_pair(tickers, data_folder='stock_data', cointegration_threshold=0.05, adf_threshold=0.05):all_pairs = analyze_all_pairs(tickers, data_folder)suitable_pairs = filter_suitable_pairs(all_pairs, cointegration_threshold, adf_threshold)if suitable_pairs.empty:return None, pd.DataFrame()best_pair = suitable_pairs.iloc[0]# ... additional code to calculate metrics for the best pair ...
这个过程能够识别显示平均反转行为最强统计证据的配对。通过应用这些严格的统计测试,可以确定几对股票,这些股票最有可能表现出统计套利策略所需的均值恢复行为。
3.配对交易策略开发
在选择合适的配对后,下一个关键步骤是制定配对交易策略。重点介绍PairTradingStrategy类的实现,该类构成了交易逻辑的核心。
A.计算关键参数:Kappa和Half-Life
在实施该策略之前,计算了两个重要参数:Kappa和Half-Life。这些参数有助于我们了解所选对的均值回归特征。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as smdef calculate_spread(stock1, stock2):return np.log(stock1['Close']) - np.log(stock2['Close'])def calculate_half_life(spread):spread_lag = spread.shift(1)spread_lag.iloc[0] = spread_lag.iloc[1]spread_ret = spread - spread_lagspread_ret.iloc[0] = spread_ret.iloc[1]spread_lag2 = sm.add_constant(spread_lag)model = sm.OLS(spread_ret, spread_lag2)res = model.fit()halflife = -np.log(2) / res.params[1]return halflifedef calculate_kappa_half_life(spread):# Calculate Kappaspread_lag = spread.shift(1)delta_spread = spread - spread_lagreg = np.polyfit(spread_lag.dropna(), delta_spread.dropna(), deg=1)kappa = -reg[0]# Calculate Half-Lifehalf_life = calculate_half_life(spread)return kappa, half_life
这些函数允许我们计算我们所选对的Kappa(平均回归率)和半衰期(价差恢复到一半到其平均值的时间)。
B.设计PairTradingStrategy类
PairTradingStrategy类使用Backtrader框架实现。以下是我们战略的核心结构:
import backtrader as btimport numpy as npfrom collections import dequeclass PairTradingStrategy(bt.Strategy):params = (('lookback', 20),('entry_threshold', 1.5), # Entry threshold in terms of standard deviations('stoploss_factor', 2.0), # Stop-loss threshold in terms of standard deviations('holding_time_factor', 1.5), # Factor to determine max holding time based on half-life('half_life', 14), # Estimated half-life of mean reversion in days('stock1', None),('stock2', None),)def __init__(self):# Initialize strategy componentsself.stock1 = self.getdatabyname(self.params.stock1)self.stock2 = self.getdatabyname(self.params.stock2)self.spread = []self.mean = Noneself.std = Noneself.entry_price = Noneself.entry_date = Noneself.max_holding_time = int(self.params.holding_time_factor * self.params.half_life)# Initialize performance trackingself.trades = []self.equity_curve = [self.broker.getvalue()]self.returns = deque(maxlen=252)self.max_drawdown = 0self.peak = self.broker.getvalue()def next(self):# Strategy logic implementation# ... (details in the following sections)def log_trade(self, action, days_held=None, reason=None):# Log trade details# ... (implementation details)def stop(self):# Calculate final performance metrics# ... (implementation details)
C.进入和退出逻辑
核心交易逻辑在next()方法中实现:
def next(self):# Calculate the spreadspread = np.log(self.stock1.close[0]) - np.log(self.stock2.close[0])self.spread.append(spread)# Wait until we have enough dataif len(self.spread) <= self.params.lookback:return# Calculate mean and standard deviationself.mean = np.mean(self.spread[-self.params.lookback:])self.std = np.std(self.spread[-self.params.lookback:])# Calculate trading thresholdsbuy_threshold = self.mean - self.params.entry_threshold * self.stdsell_threshold = self.mean + self.params.entry_threshold * self.std# Trading logicif not self.position:if spread < buy_threshold:self.buy(data=self.stock1)self.sell(data=self.stock2)self.entry_price = spreadself.entry_date = len(self)self.log_trade('ENTRY LONG')elif spread > sell_threshold:self.sell(data=self.stock1)self.buy(data=self.stock2)self.entry_price = spreadself.entry_date = len(self)self.log_trade('ENTRY SHORT')else:# Exit logic# ... (implementation details for exit conditions)
D.风险管理技术
我们的战略结合了几种风险管理技术:
# Inside the next() method, for existing positionsif abs(spread - self.entry_price) > self.params.stoploss_factor * self.std:self.close(data=self.stock1)self.close(data=self.stock2)self.log_trade('STOP-LOSS', days_since_entry, reason="Stop-Loss Hit")# Max holding time checkdays_since_entry = len(self) - self.entry_dateif days_since_entry >= self.max_holding_time:self.close(data=self.stock1)self.close(data=self.stock2)self.log_trade('EXIT', days_since_entry, reason="Max Holding Time")
- 止损:如果利差超过某个阈值,我们就退出交易。
- 最大持有时间:我们根据计算的半衰期限制每笔交易的持续时间。
- 位置大小:虽然本代码片段中没有明确显示,但适当的位置大小至关重要,应根据帐户大小和风险承受能力来实施。
通过实施这些组件,创建了一个强大的配对交易策略,该策略利用平均回归机会,同时有效管理风险,这构成了统计套利系统的核心。
4.回测引擎
在制定我们的配对交易策略后,下一个关键步骤是在历史数据上测试其表现。这就是我们的反向测试引擎发挥作用的地方,如何实施和使用这个引擎来评估我们的战略。
A.Backtrader框架简介
我们的回测引擎是使用Backtrader框架构建的,该框架为测试交易策略提供了一个灵活而强大的平台。
B.实现自定义BacktestEngine类
提供了一个自定义的BacktestEngine类,该类环绕着Backtrader的功能。以下是实现:
import backtrader as btimport pandas as pdimport matplotlib.pyplot as pltfrom tabulate import tabulateclass BacktestEngine:def __init__(self, strategy_class, df1, df2, initial_capital=100000, commission=0.001):self.cerebro = bt.Cerebro()self.strategy_class = strategy_classself.df1 = df1self.df2 = df2self.initial_capital = initial_capitalself.commission = commissionself.results = Nonedef add_data(self):data1 = bt.feeds.PandasData(dataname=self.df1, name="stock1")data2 = bt.feeds.PandasData(dataname=self.df2, name="stock2")self.cerebro.adddata(data1)self.cerebro.adddata(data2)def set_strategy(self, **kwargs):self.cerebro.addstrategy(self.strategy_class, **kwargs)def set_broker(self, initial_capital=None, commission=None):if initial_capital is None:initial_capital = self.initial_capitalif commission is None:commission = self.commissiondef run(self):self.add_data()self.set_broker()self.results = self.cerebro.run()
该类封装了设置回测环境、添加数据、设置策略和代理参数以及运行回测的过程。
C.模拟历史数据的交易
我们的BacktestEngine类的run方法负责模拟历史数据的交易。它使用Backtrader引擎在提供的数据上运行策略:
def run(self):self.add_data()self.set_broker()self.results = self.cerebro.run()
此方法添加数据,设置代理,然后运行回测,存储结果以供以后分析。
D.计算绩效指标
运行回测后,我们计算各种性能指标来评估我们的策略。BacktestEngine类包括用于此目的的方法:
def get_metrics(self):if not self.results:return {"Error": "No backtest results available. Please run the backtest first."}strat = self.results[0]if not hasattr(strat, 'metrics'):return {"Error": "No metrics found in the strategy. Make sure to implement custom metrics in your strategy."}return strat.metricsdef print_metrics(self):metrics = self.get_metrics()if isinstance(metrics, dict) and "Error" in metrics:print(metrics["Error"])returntable_data = [["Metric", "Value"]]for key, value in metrics.items():if isinstance(value, float):table_data.append([key, f"{value:.2f}"])else:table_data.append([key, value])print("\nBacktest Results:")print(tabulate(table_data, headers="firstrow", tablefmt="grid"))
这些方法检索并打印在回测期间计算的性能指标。此外,该引擎提供了可视化结果的方法:
def plot_equity_curve(self):if not self.results:print("No results available. Make sure to run the backtest first.")returnstrat = self.results[0]if not hasattr(strat, 'equity_curve'):print("No equity curve data found in the strategy.")return# Convert equity curve to pandas Seriesequity_curve = pd.Series(strat.equity_curve, index=self.df1.index[:len(strat.equity_curve)])# Calculate drawdowndrawdown = (equity_curve.cummax() - equity_curve) / equity_curve.cummax()# Create figure with two subplotsfig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), gridspec_kw={'height_ratios': [3, 1]})fig.suptitle('Equity Curve and Drawdown', fontsize=16)# Plot equity curveax1.plot(equity_curve.index, equity_curve.values, label='Equity Curve', color='blue')ax1.set_title('Equity Curve')ax1.set_ylabel('Portfolio Value')ax1.legend()ax1.grid(True)# Plot drawdownax2.fill_between(drawdown.index, drawdown.values, 0, alpha=0.3, color='red', label='Drawdown')ax2.set_title('Drawdown')ax2.set_ylabel('Drawdown')ax2.set_xlabel('Date')ax2.legend()ax2.grid(True)# Format x-axisplt.gcf().autofmt_xdate()# Add strategy performance metrics as textmetrics = self.get_metrics()metrics_text = (f"Total Return: {metrics['Total Return (%)']:.2f}%\n"f"Sharpe Ratio: {metrics['Sharpe Ratio']:.2f}\n"f"Max Drawdown: {metrics['Max Drawdown (%)']:.2f}%\n"f"Win Rate: {metrics['Win Rate (%)']:.2f}%")fig.text(0.02, 0.02, metrics_text, fontsize=10, va='bottom')# Adjust layoutplt.tight_layout(rect=[0, 0.03, 1, 0.95])# Show plotplt.show()
这种方法创建了战略绩效的全面可视化,包括收益曲线和回撤。通过实施这个回测引擎,我们可以根据历史数据彻底评估我们的配对交易策略,计算关键性能指标,并可视化结果。这构成了我们项目的关键一步,使我们能够在进入优化和现实世界实施之前评估战略的有效性。
5.贝叶斯优化
在实施我们的回测引擎后,下一步是优化策略参数。我们使用贝叶斯优化,这是找到交易策略最佳参数的有效方法。
A.参数优化的需要
我们的配对交易策略涉及几个参数,这些参数可能会显著影响其表现。这些包括回顾期、进入阈值、止损系数等。优化这些参数可能会提高策略的性能。
B.贝叶斯优化简介
贝叶斯优化是优化黑盒函数的强大技术,当函数的评估成本高昂时尤为有用——就像我们的回测过程一样。它使用概率模型来指导最佳参数的搜索。
C.定义参数空间
在我们的实现中,我们定义了优化过程的参数空间。以下是我们如何设置它:
from skopt import gp_minimizefrom skopt.space import Real, Integerfrom skopt.utils import use_named_argsdef bayesian_optimization(df1, df2, param_ranges, n_calls=50, initial_capital=100000, commission=0.001):space = [Integer(param_ranges['lookback'][0].min(), param_ranges['lookback'][0].max(), name='lookback'),Real(param_ranges['entry_threshold'][0].min(), param_ranges['entry_threshold'][0].max(), name='entry_threshold'),Real(param_ranges['stoploss_factor'][0].min(), param_ranges['stoploss_factor'][0].max(), name='stoploss_factor'),Real(param_ranges['holding_time_factor'][0].min(), param_ranges['holding_time_factor'][0].max(), name='holding_time_factor'),]fixed_half_life = param_ranges['half_life'][0]# ... rest of the function
此代码定义了我们参数的搜索空间,包括回溯期、进入阈值、止损因子和保持时间因子。
D.创建目标功能
在案例中,基于策略夏普比率:
def objective(params, df1, df2, initial_capital=100000, commission=0.001):lookback, entry_threshold, stoploss_factor, holding_time_factor, half_life = paramsengine = BacktestEngine(strategy_class=PairTradingStrategy,df1=df1,df2=df2,initial_capital=initial_capital)engine.set_strategy(lookback=int(lookback),entry_threshold=entry_threshold,stoploss_factor=stoploss_factor,holding_time_factor=holding_time_factor,half_life=half_life,stock1="stock1",stock2="stock2")engine.set_broker(commission=commission, initial_capital=initial_capital)engine.run()metrics = engine.get_metrics()# We want to maximize Sharpe Ratio, so we return its negativereturn -metrics.get('Sharpe Ratio', 0)
该函数使用给定的参数运行回测,并返回负夏普比率(我们否定它,因为优化算法最小化了目标函数,我们希望最大化夏普比率)。
E.运行优化过程
最后,我们运行贝叶斯优化过程:
@use_named_args(space)def objective_wrapper(**params):params_list = list(params.values()) + [fixed_half_life]return objective(params_list, df1, df2, initial_capital, commission)def callback(res):n = len(res.x_iters)print(f"Optimization progress: {n / n_calls * 100:.2f}%")result = gp_minimize(objective_wrapper, space, n_calls=n_calls, random_state=42, callback=callback)best_params = {'lookback': int(result.x[0]),'entry_threshold': result.x[1],'stoploss_factor': result.x[2],'holding_time_factor': result.x[3],'half_life': fixed_half_life}return best_params, -result.fun # Return best parameters and best Sharpe Ratio
此代码运行优化过程,打印进度更新,并返回找到的最佳参数以及相应的夏普比率。通过实施贝叶斯优化,可以有效地搜索参数空间,以找到为我们的配对交易策略产生最佳性能的配置。然后,这种优化策略可以进一步测试,并可能部署在实时交易场景中。
6.结果分析
在实施我们的配对交易策略、回测并优化其参数后,最后的关键步骤是分析结果。这项分析有助于我们了解我们战略的表现,并就其潜在的现实世界应用做出明智的决定。
A.可视化收益曲线
BacktestEngine提供的关键可视化之一是收益曲线。这让我们清楚地了解了我们的投资组合价值如何随着时间的推移而变化。我们BacktestEngine类中的plot_equity_curve方法生成以下可视化:
def plot_equity_curve(self):if not self.results:print("No results available. Make sure to run the backtest first.")returnstrat = self.results[0]if not hasattr(strat, 'equity_curve'):print("No equity curve data found in the strategy.")return# Convert equity curve to pandas Seriesequity_curve = pd.Series(strat.equity_curve, index=self.df1.index[:len(strat.equity_curve)])# Calculate drawdowndrawdown = (equity_curve.cummax() - equity_curve) / equity_curve.cummax()# Create figure with two subplotsfig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), gridspec_kw={'height_ratios': [3, 1]})fig.suptitle('Equity Curve and Drawdown', fontsize=16)# Plot equity curveax1.plot(equity_curve.index, equity_curve.values, label='Equity Curve', color='blue')ax1.set_title('Equity Curve')ax1.set_ylabel('Portfolio Value')ax1.legend()ax1.grid(True)# Plot drawdownax2.fill_between(drawdown.index, drawdown.values, 0, alpha=0.3, color='red', label='Drawdown')ax2.set_title('Drawdown')ax2.set_ylabel('Drawdown')ax2.set_xlabel('Date')ax2.legend()ax2.grid(True)# Format x-axisplt.gcf().autofmt_xdate()# Add strategy performance metrics as textmetrics = self.get_metrics()metrics_text = (f"Total Return: {metrics['Total Return (%)']:.2f}%\n"f"Sharpe Ratio: {metrics['Sharpe Ratio']:.2f}\n"f"Max Drawdown: {metrics['Max Drawdown (%)']:.2f}%\n"f"Win Rate: {metrics['Win Rate (%)']:.2f}%")fig.text(0.02, 0.02, metrics_text, fontsize=10, va='bottom')# Adjust layoutplt.tight_layout(rect=[0, 0.03, 1, 0.95])# Show plotplt.show()
这种方法创建了一个全面的可视化:
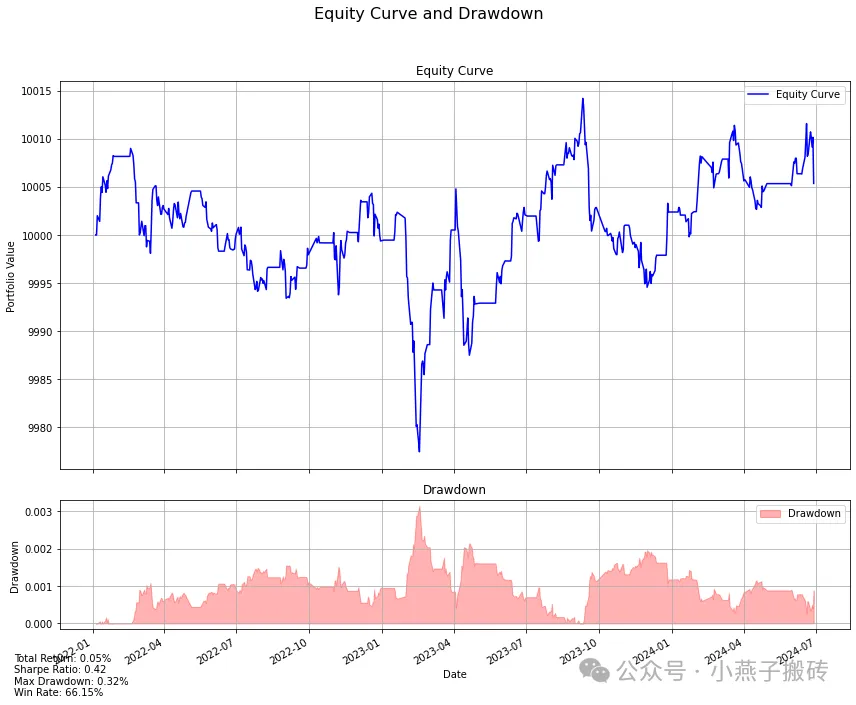
B.分析交易表
为了获得单个交易的详细视图,我们可以生成一个交易表。我们BacktestEngine类中的print_trade_table方法提供以下功能:
def print_trade_table(self, num_trades=None):if not self.results:print("No results available. Make sure to run the backtest first.")returnstrat = self.results[0]if not hasattr(strat, 'trades'):print("No trade information found in the strategy. Make sure to log trades in your strategy.")returntrades = strat.tradesif num_trades is not None:trades = trades[:num_trades]trade_data = []for trade in trades:trade_data.append([trade.get('entry_date', 'N/A'),trade.get('exit_date', 'N/A'),trade.get('days_held', 'N/A'),f"{trade.get('pnl', 'N/A'):.2f}",f"{trade.get('pnl_pct', 'N/A'):.2f}%",f"{trade.get('entry_price1', 'N/A'):.2f}",f"{trade.get('entry_price2', 'N/A'):.2f}",f"{trade.get('exit_price1', 'N/A'):.2f}",f"{trade.get('exit_price2', 'N/A'):.2f}",trade.get('exit_type', 'N/A'),trade.get('exit_reason', 'N/A')])headers = ["Entry Date", "Exit Date", "Days Held", "PnL", "PnL %","Entry Price 1", "Entry Price 2", "Exit Price 1", "Exit Price 2", "Exit Type", "Exit Reason"]print("\nTrade History:")print(tabulate(trade_data, headers=headers, tablefmt="grid"))
这种方法提供了每笔交易的详细视图,包括进入和退出日期、利润/损失以及退出原因。
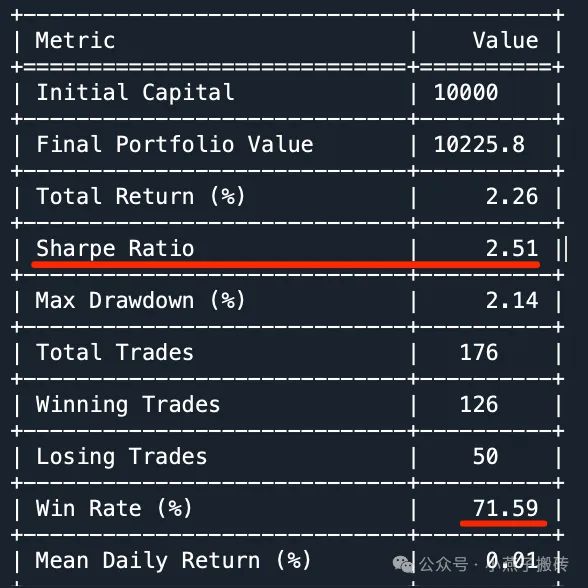
C.关键绩效指标讨论我们的BacktestEngine计算并存储各种性能指标。我们可以使用get_metrics方法访问这些指标:
def get_metrics(self):if not self.results:return {"Error": "No backtest results available. Please run the backtest first."}strat = self.results[0]if not hasattr(strat, 'metrics'):return {"Error": "No metrics found in the strategy. Make sure to implement custom metrics in your strategy."}return strat.metricsdef stop(self):# Calculate final metricsself.total_trades = len(self.trades)self.winning_trades = sum(1 for trade in self.trades if trade['pnl'] > 0)self.losing_trades = sum(1 for trade in self.trades if trade['pnl'] <= 0)self.win_rate = self.winning_trades / self.total_trades if self.total_trades > 0 else 0self.total_return = (self.equity_curve[-1] - self.equity_curve[0]) / self.equity_curve[0]self.mean_return = np.mean(self.returns) if self.returns else 0self.std_return = np.std(self.returns) if self.returns else 0self.sharpe_ratio = np.sqrt(252) * self.mean_return / self.std_return if self.std_return != 0 else 0# Store all metrics in a dictionary for easy accessself.metrics = {'Initial Capital': self.equity_curve[0],'Final Portfolio Value': self.equity_curve[-1],'Total Return (%)': self.total_return * 100,'Sharpe Ratio': self.sharpe_ratio,'Max Drawdown (%)': self.max_drawdown * 100,'Total Trades': self.total_trades,'Winning Trades': self.winning_trades,'Losing Trades': self.losing_trades,'Win Rate (%)': self.win_rate * 100,'Mean Daily Return (%)': self.mean_return * 100,'Std Dev of Daily Return (%)': self.std_return * 100}
这些指标提供了该战略表现的全面视图,包括盈利能力、风险调整后的回报和交易统计数据。**************************************************Best parameters found:lookback: 5entry_threshold: 1.7398419571642885stoploss_factor: 2.8542357050405993holding_time_factor: 1.6608547870665733half_life: 12.528305901631226Best Sharpe Ratio: 1.5644852160138814****************************************************************************************************Final Backtest Results:
Backtest Results:+—————————–+———-+| Metric | Value |+=============================+==========+| Initial Capital | 10000 |+—————————–+———-+| Final Portfolio Value | 10008.9 |+—————————–+———-+| Total Return (%) | 0.09 |+—————————–+———-+| Sharpe Ratio | 1.56 |+—————————–+———-+| Max Drawdown (%) | 0.09 |+—————————–+———-+| Total Trades | 74 |+—————————–+———-+| Winning Trades | 63 |+—————————–+———-+| Losing Trades | 11 |+—————————–+———-+| Win Rate (%) | 85.14 |+—————————–+———-+| Mean Daily Return (%) | 0 |+—————————–+———-+| Std Dev of Daily Return (%) | 0 |+—————————–+———-+
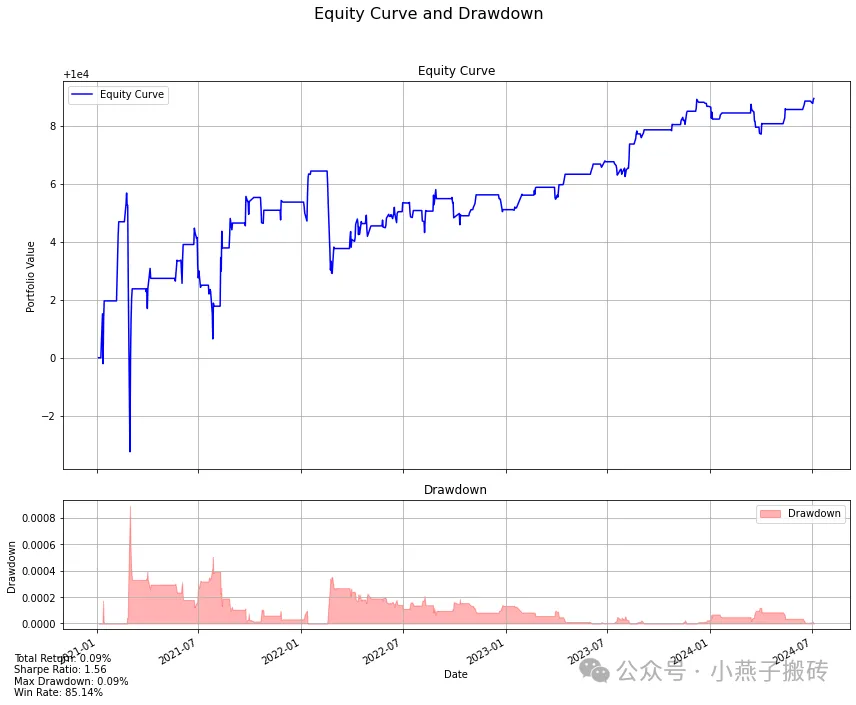
一开始的数据不太正常,可能还要再查一下爬虫下来的数据情况再分析。
D.将战略绩效与基准进行比较
虽然在提供的代码中没有明确实施,但重要的是将我们策略的表现与相关基准进行比较,例如整体市场表现或单个股票的简单买入并持有策略。这种比较有助于我们了解我们的策略是否真正增加了价值,超出了使用更简单、不太复杂的方法可以实现的价值。
7.未来的改进
虽然我们目前实施的StatArb对交易策略提供了坚实的基础,但有几个领域我们有可能增强和扩展该系统。这次没有明确概述未来的改进,但我们可以根据定量交易中的当前实施和常见做法推断出一些潜在的增强。
A.扩大股票池
我们目前的实现使用50个股票代码的预定义列表。一个潜在的改进是扩大股票池,以包括更多的股票甚至其他资产类别。这可能涉及:
- 根据某些标准(例如市值、行业、流动性)实现股票选择过程的自动化。
- 实施一个动态的股票宇宙,根据市场条件定期更新。
- 将策略扩展到其他资产类别,如ETF、期货或外汇对。
B.纳入基本数据
我们目前的战略主要依赖于价格数据。纳入基本数据可能会改善配对选择过程和整体战略绩效。这可能包括:
- 使用财务比率来识别潜在配对的类似公司。
- 将收益数据或其他财务指标纳入交易信号。
- 考虑可能影响配对关系的宏观经济指标。
C.探索机器学习以选择配对
虽然我们目前的配对选择过程使用共整合和相关性等统计方法,但机器学习技术可能会增强这一过程。一些可能性包括:
- 使用聚类算法来识别类似股票的群体。
- 实施分类模型来预测哪些对可能表现良好。
- 应用强化学习技术来动态调整策略参数。
D.加强风险管理
虽然我们目前的实施包括一些风险管理技术,但这一领域可以进一步改进:
# Current risk management in the strategyif abs(spread - self.entry_price) > self.params.stoploss_factor * self.std:self.close(data=self.stock1)self.close(data=self.stock2)self.log_trade('STOP-LOSS', days_since_entry, reason="Stop-Loss Hit")
潜在的增强功能可能包括:
- 实施更复杂的止损机制。
- 根据波动性或其他风险指标添加头寸规模。
- 在交易多对时,将风险平价方法纳入投资组合构建。
E.改进执行建模
我们目前的回测假设执行完美,这在实时交易中是不现实的。该领域的改进可能包括:
- 更准确地建模滑点和交易成本。
- 实施限价订单而不是市场订单。
- 考虑流动性限制及其对交易执行的影响。
F. 扩大绩效分析
虽然我们目前的分析提供了良好的见解,但我们可以进一步增强它:
# Current performance metricsself.metrics = {'Initial Capital': self.equity_curve[0],'Final Portfolio Value': self.equity_curve[-1],'Total Return (%)': self.total_return * 100,'Sharpe Ratio': self.sharpe_ratio,'Max Drawdown (%)': self.max_drawdown * 100,'Total Trades': self.total_trades,'Winning Trades': self.winning_trades,'Losing Trades': self.losing_trades,'Win Rate (%)': self.win_rate * 100,'Mean Daily Return (%)': self.mean_return * 100,'Std Dev of Daily Return (%)': self.std_return * 100}
潜在的改进包括:
- 实施更高级的风险调整回报指标(例如,Sortino比率,Calmar比率)。
- 进行更详细的缩减分析。
- 进行归因分析以了解回报来源。
通过实施这些改进,我们可以潜在地提高StatArb Pairs交易策略的稳健性、性能和适用性。
8.结论
A.统计套利在现代市场中的潜力
实例展示了统计套利策略在当今市场的持续相关性和潜力。通过利用先进的统计技术和机器学习优化,我们已经展示了如何识别和利用微妙的市场效率。我们开发的配对交易方法具有几个优势:
- 市场中立性,可以提供与整体市场走势无关的回报。
- 通过平衡的多头-空头交易结构进行风险管理。
- 通过参数优化适应各种市场条件。
B.关于定量交易策略未来的一些想法
像我们开发的量化交易策略将继续在金融市场中发挥关键作用。然而,随着市场越来越高效和竞争,持续创新和完善的重要性怎么强调都不为过。未来发展的一些关键领域包括:
- 结合替代数据源以获得独特的见解。
- 利用先进的机器学习技术来改进模式识别和预测。
- 扩展到其他资产类别和全球市场。
- 增强执行算法,以最大限度地减少市场影响和交易成本。
总之,实例结合统计分析、算法交易和机器学习优化的力量。随着金融格局的不断发展,像这样的策略——不断完善和调整——将成为寻求驾驭现代市场复杂性的投资者的关键工具。
实例的全部代码,以沪深A股为例:
Jupyter Notebook可在以下地址找到(以美股为例)GitHub:https://github.com/theanh97/Statistical-Arbitrage-Bayesian-Optimized-Kappa-Half-life-Pairs-Trading-Engine/
@author: Shenxiaoyan
"""
import yfinance as yf
import os
from datetime import datetime
# # List of 50 stock tickers
# list_tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'TSLA', 'BRK-A', 'V', 'JPM', 'JNJ', 'WMT', 'UNH', 'MA', 'PG', 'NVDA', 'HD', 'DIS', 'PYPL', 'BAC', 'CMCSA', 'ADBE', 'XOM', 'INTC', 'VZ', 'NFLX', 'T', 'CRM', 'ABT', 'CSCO', 'PEP', 'PFE', 'KO', 'MRK', 'NKE', 'CVX', 'WFC', 'ORCL', 'MCD', 'COST', 'ABBV', 'MDT', 'TMO', 'ACN', 'HON', 'UNP', 'IBM', 'UPS', 'LIN', 'LLY', 'AMT']
# list_tickers = [
# '688981.ss', '688111.ss', '688041.ss', '688012.ss', '603986.ss', '603501.ss', '603288.ss', '603259.ss',
# '601988.ss', '601985.ss', '601919.ss', '601899.ss', '601888.ss', '601857.ss', '601728.ss', '601669.ss',
# '601668.ss', '601658.ss', '601633.ss', '601628.ss', '601601.ss', '601398.ss', '601390.ss', '601328.ss',
# '601318.ss', '601288.ss', '601225.ss', '601166.ss', '601088.ss', '601012.ss', '600941.ss', '600900.ss',
# '600887.ss', '600809.ss', '600690.ss', '600519.ss', '600438.ss', '600436.ss', '600406.ss', '600309.ss',
# '600276.ss', '600150.ss', '600104.ss', '600089.ss', '600050.ss', '600048.ss', '600036.ss', '600031.ss',
# '600030.ss', '600028.ss',
# ]
list_tickers = [
'600941.ss', '601398.ss', '601939.ss', '600519.ss', '601288.ss', '601857.ss', '601988.ss', '600938.ss',
'601628.ss', '600036.ss', '300750.sz', '601088.ss', '600028.ss', '601318.ss', '600900.ss', '002594.sz',
'601728.ss', '601328.ss', '601658.ss', '000858.sz', '601138.ss', '000333.sz', '601899.ss', '688981.ss',
'601166.ss', '688021.ss', '688701.ss', '688096.ss', '002629.sz', '688217.ss', '000982.sz', '688565.ss',
'688178.ss', '688004.ss', '603021.ss', '600539.ss', '688659.ss', '688679.ss', '603272.ss', '688215.ss',
'002193.sz', '600455.ss', '600768.ss', '688681.ss', '300478.sz', '688067.ss', '000668.sz', '300929.sz',
'603316.ss', '688296.ss'
]
# list_tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'TSLA', 'BRK-A', 'V', 'JPM', 'JNJ']
# Set start and end times
start_time = '2021-01-01'
end_time = '2024-07-29'
# Create a folder to save data if it doesn't exist
folder_name = 'stock_data'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# Function to download and save data for a stock
def download_and_save_stock_data(ticker):
try:
# Download data
data = yf.download(ticker, start=start_time, end=end_time)
# Create file name
file_name = os.path.join(folder_name, f"{ticker}.csv")
# Save data to CSV file
data.to_csv(file_name)
print(f"Downloaded and saved data for {ticker}")
except Exception as e:
print(f"Error downloading data for {ticker}: {str(e)}")
# Download and save data for all stocks
for ticker in list_tickers:
download_and_save_stock_data(ticker)
print("Completed downloading data for all stocks.")
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import coint, adfuller
import os
from itertools import combinations
def load_stock_data(ticker, data_folder='stock_data'):
"""Load stock data from CSV file."""
return pd.read_csv(os.path.join(data_folder, f'{ticker}.csv'), index_col='Date', parse_dates=True)
def calculate_log_spread_and_zscore(stock1, stock2):
"""Calculate log spread and its z-score."""
log_spread = np.log(stock1['Close']) - np.log(stock2['Close'])
z_score = (log_spread - log_spread.mean()) / log_spread.std()
return log_spread, z_score
def analyze_pair(stock1, stock2):
"""Analyze a pair of stocks for cointegration, correlation, and stationarity."""
log_spread, z_score = calculate_log_spread_and_zscore(stock1, stock2)
# Check Cointegration
score, pvalue, _ = coint(stock1['Close'], stock2['Close'])
# Calculate Correlation
correlation = stock1['Close'].corr(stock2['Close'])
# Augmented Dickey-Fuller Test on log spread
adf_result = adfuller(log_spread)
return {
'cointegration_pvalue': pvalue,
'correlation': correlation,
'adf_pvalue': adf_result[1],
'log_spread': log_spread,
'z_score': z_score
}
def analyze_all_pairs(tickers, data_folder='stock_data'):
"""Analyze all possible pairs from the given list of tickers."""
results = []
for ticker1, ticker2 in combinations(tickers, 2):
try:
stock1 = load_stock_data(ticker1, data_folder)
stock2 = load_stock_data(ticker2, data_folder)
# Ensure both stocks have the same date range
common_dates = stock1.index.intersection(stock2.index)
stock1 = stock1.loc[common_dates]
stock2 = stock2.loc[common_dates]
result = analyze_pair(stock1, stock2)
results.append({
'pair': f'{ticker1}-{ticker2}',
'cointegration_pvalue': result['cointegration_pvalue'],
'correlation': result['correlation'],
'adf_pvalue': result['adf_pvalue'],
'mean_zscore': result['z_score'].mean(),
'std_zscore': result['z_score'].std()
})
except Exception as e:
print(f"Error analyzing pair {ticker1}-{ticker2}: {str(e)}")
return pd.DataFrame(results)
def filter_suitable_pairs(df_results, cointegration_threshold=0.05, adf_threshold=0.05):
"""Filter pairs suitable for pair trading based on cointegration and stationarity."""
return df_results[
(df_results['cointegration_pvalue'] < cointegration_threshold) &
(df_results['adf_pvalue'] < adf_threshold)
].sort_values('correlation', ascending=False)
def find_best_pair(tickers, data_folder='stock_data', cointegration_threshold=0.05, adf_threshold=0.05):
"""Find the best pair for pair trading from the given list of tickers."""
all_pairs = analyze_all_pairs(tickers, data_folder)
suitable_pairs = filter_suitable_pairs(all_pairs, cointegration_threshold, adf_threshold)
if suitable_pairs.empty:
return None, pd.DataFrame() # Return None and an empty DataFrame instead of a string
best_pair = suitable_pairs.iloc[0]
stock1, stock2 = best_pair['pair'].split('-')
# Load data for the best pair to calculate additional metrics
stock1_data = load_stock_data(stock1, data_folder)
stock2_data = load_stock_data(stock2, data_folder)
common_dates = stock1_data.index.intersection(stock2_data.index)
stock1_data = stock1_data.loc[common_dates]
stock2_data = stock2_data.loc[common_dates]
log_spread, z_score = calculate_log_spread_and_zscore(stock1_data, stock2_data)
return {
'stock1': stock1,
'stock2': stock2,
'correlation': best_pair['correlation'],
'cointegration_pvalue': best_pair['cointegration_pvalue'],
'adf_pvalue': best_pair['adf_pvalue'],
'mean_zscore': best_pair['mean_zscore'],
'std_zscore': best_pair['std_zscore'],
'log_spread': log_spread,
'z_score': z_score
}, suitable_pairs
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
def calculate_spread(stock1, stock2):
return np.log(stock1['Close']) - np.log(stock2['Close'])
def calculate_half_life(spread):
spread_lag = spread.shift(1)
spread_lag.iloc[0] = spread_lag.iloc[1]
spread_ret = spread - spread_lag
spread_ret.iloc[0] = spread_ret.iloc[1]
spread_lag2 = sm.add_constant(spread_lag)
model = sm.OLS(spread_ret, spread_lag2)
res = model.fit()
halflife = -np.log(2) / res.params[1]
return halflife
def calculate_kappa_half_life(spread):
# Calculate Kappa
spread_lag = spread.shift(1)
delta_spread = spread - spread_lag
reg = np.polyfit(spread_lag.dropna(), delta_spread.dropna(), deg=1)
kappa = -reg[0]
# Calculate Half-Life
half_life = calculate_half_life(spread)
return kappa, half_life
def calculate_kappa_and_half_life(stock1_data, stock2_data, plot=True):
# Ensure both stocks have the same date range
common_dates = stock1_data.index.intersection(stock2_data.index)
stock1_data = stock1_data.loc[common_dates]
stock2_data = stock2_data.loc[common_dates]
# Calculate spread
spread = calculate_spread(stock1_data, stock2_data)
# Calculate Kappa and Half-Life
kappa, half_life = calculate_kappa_half_life(spread)
if plot:
# Plot the spread
plt.figure(figsize=(12, 6))
plt.plot(spread)
plt.title(f'Price Spread')
plt.xlabel('Date')
plt.ylabel('Spread')
plt.show()
return kappa, half_life
import backtrader as bt
import numpy as np
from collections import deque
class PairTradingStrategy(bt.Strategy):
params = (
('lookback', 20),
('entry_threshold', 1.5), # Entry threshold in terms of standard deviations
('stoploss_factor', 2.0), # Stop-loss threshold in terms of standard deviations
('holding_time_factor', 1.5), # Factor to determine max holding time based on half-life
('half_life', 14), # Estimated half-life of mean reversion in days
('stock1', None),
('stock2', None),
)
def __init__(self):
# Get the data for the two stocks
self.stock1 = self.getdatabyname(self.params.stock1)
self.stock2 = self.getdatabyname(self.params.stock2)
# Initialize spread and mean/std
self.spread = []
self.mean = None
self.std = None
self.entry_price = None # Entry price for the current position
self.entry_date = None # Entry date for the current position
# Calculate max holding time
self.max_holding_time = int(self.params.holding_time_factor * self.params.half_life)
# Custom metrics tracking
self.trades = []
self.equity_curve = [self.broker.getvalue()]
self.returns = deque(maxlen=252) # For annual Sharpe ratio
self.max_drawdown = 0
self.peak = self.broker.getvalue()
def next(self):
# Calculate the spread
spread = np.log(self.stock1.close[0]) - np.log(self.stock2.close[0])
self.spread.append(spread)
# Wait until we have enough data
if len(self.spread) <= self.params.lookback:
return
# Calculate mean and standard deviation
self.mean = np.mean(self.spread[-self.params.lookback:])
self.std = np.std(self.spread[-self.params.lookback:])
# Calculate trading thresholds
buy_threshold = self.mean - self.params.entry_threshold * self.std
sell_threshold = self.mean + self.params.entry_threshold * self.std
# Trading logic
# No existing position
if not self.position:
if spread < buy_threshold:
self.buy(data=self.stock1)
self.sell(data=self.stock2)
self.entry_price = spread
self.entry_date = len(self)
self.log_trade('ENTRY LONG')
elif spread > sell_threshold:
self.sell(data=self.stock1)
self.buy(data=self.stock2)
self.entry_price = spread
self.entry_date = len(self)
self.log_trade('ENTRY SHORT')
# Existing position
else:
# Check for exit conditions
days_since_entry = len(self) - self.entry_date
# Trong phần exit logic
if (self.position.size > 0 and spread >= self.mean) or \
(self.position.size < 0 and spread <= self.mean):
self.close(data=self.stock1)
self.close(data=self.stock2)
self.log_trade('EXIT', days_since_entry, reason="Spread Reversion")
elif days_since_entry >= self.max_holding_time:
self.close(data=self.stock1)
self.close(data=self.stock2)
self.log_trade('EXIT', days_since_entry, reason="Max Holding Time")
return
# Check for stop-loss
stop_loss_threshold = self.params.stoploss_factor * self.std
if abs(spread - self.entry_price) > stop_loss_threshold:
self.close(data=self.stock1)
self.close(data=self.stock2)
self.log_trade('STOP-LOSS', days_since_entry, reason="Stop-Loss Hit")
# Update metrics
current_value = self.broker.getvalue()
self.equity_curve.append(current_value)
# Calculate return
if len(self.equity_curve) > 1:
daily_return = (current_value - self.equity_curve[-2]) / self.equity_curve[-2]
self.returns.append(daily_return)
# Update max drawdown
if current_value > self.peak:
self.peak = current_value
dd = (self.peak - current_value) / self.peak
if dd > self.max_drawdown:
self.max_drawdown = dd
def log_trade(self, action, days_held=None, reason=None):
if action.startswith('ENTRY'):
self.entry_date = len(self)
self.entry_price1 = self.stock1.close[0]
self.entry_price2 = self.stock2.close[0]
elif action in ['EXIT', 'STOP-LOSS']:
exit_price1 = self.stock1.close[0]
exit_price2 = self.stock2.close[0]
pnl = self.broker.getvalue() - self.equity_curve[-1]
pnl_pct = (pnl / self.equity_curve[-1]) * 100
self.trades.append({
'entry_date': self.data.datetime.date(-days_held) if days_held is not None else None,
'exit_date': self.data.datetime.date(0),
'days_held': days_held,
'pnl': pnl,
'pnl_pct': pnl_pct,
'entry_price1': self.entry_price1,
'entry_price2': self.entry_price2,
'exit_price1': exit_price1,
'exit_price2': exit_price2,
'exit_type': action,
'exit_reason': reason
})
def stop(self):
# Calculate final metrics
self.total_trades = len(self.trades)
self.winning_trades = sum(1 for trade in self.trades if trade['pnl'] > 0)
self.losing_trades = sum(1 for trade in self.trades if trade['pnl'] <= 0)
self.win_rate = self.winning_trades / self.total_trades if self.total_trades > 0 else 0
self.total_return = (self.equity_curve[-1] - self.equity_curve[0]) / self.equity_curve[0]
self.mean_return = np.mean(self.returns) if self.returns else 0
self.std_return = np.std(self.returns) if self.returns else 0
self.sharpe_ratio = np.sqrt(252) * self.mean_return / self.std_return if self.std_return != 0 else 0
# Store all metrics in a dictionary for easy access
self.metrics = {
'Initial Capital': self.equity_curve[0],
'Final Portfolio Value': self.equity_curve[-1],
'Total Return (%)': self.total_return * 100,
'Sharpe Ratio': self.sharpe_ratio,
'Max Drawdown (%)': self.max_drawdown * 100,
'Total Trades': self.total_trades,
'Winning Trades': self.winning_trades,
'Losing Trades': self.losing_trades,
'Win Rate (%)': self.win_rate * 100,
'Mean Daily Return (%)': self.mean_return * 100,
'Std Dev of Daily Return (%)': self.std_return * 100
}
import backtrader as bt
import pandas as pd
import matplotlib.pyplot as plt
from tabulate import tabulate
class BacktestEngine:
def __init__(self, strategy_class, df1, df2, initial_capital=100000, commission=0.001):
self.cerebro = bt.Cerebro()
self.strategy_class = strategy_class
self.df1 = df1
self.df2 = df2
self.initial_capital = initial_capital
self.commission = commission
self.results = None
def add_data(self):
data1 = bt.feeds.PandasData(dataname=self.df1, name="stock1")
data2 = bt.feeds.PandasData(dataname=self.df2, name="stock2")
self.cerebro.adddata(data1)
self.cerebro.adddata(data2)
def set_strategy(self, **kwargs):
self.cerebro.addstrategy(self.strategy_class, **kwargs)
def set_broker(self, initial_capital=None, commission=None):
if initial_capital is None:
initial_capital = self.initial_capital
if commission is None:
commission = self.commission
def run(self):
self.add_data()
self.set_broker()
self.results = self.cerebro.run()
def get_metrics(self):
if not self.results:
return {"Error": "No backtest results available. Please run the backtest first."}
strat = self.results[0]
if not hasattr(strat, 'metrics'):
return {"Error": "No metrics found in the strategy. Make sure to implement custom metrics in your strategy."}
return strat.metrics
def print_metrics(self):
metrics = self.get_metrics()
if isinstance(metrics, dict) and "Error" in metrics:
print(metrics["Error"])
return
table_data = [["Metric", "Value"]]
for key, value in metrics.items():
if isinstance(value, float):
table_data.append([key, f"{value:.2f}"])
else:
table_data.append([key, value])
print("\nBacktest Results:")
print(tabulate(table_data, headers="firstrow", tablefmt="grid"))
def print_trade_table(self, num_trades=None):
if not self.results:
print("No results available. Make sure to run the backtest first.")
return
strat = self.results[0]
if not hasattr(strat, 'trades'):
print("No trade information found in the strategy. Make sure to log trades in your strategy.")
return
trades = strat.trades
if num_trades is not None:
trades = trades[:num_trades]
trade_data = []
for trade in trades:
trade_data.append([
trade.get('entry_date', 'N/A'),
trade.get('exit_date', 'N/A'),
trade.get('days_held', 'N/A'),
f"{trade.get('pnl', 'N/A'):.2f}",
f"{trade.get('pnl_pct', 'N/A'):.2f}%",
f"{trade.get('entry_price1', 'N/A'):.2f}",
f"{trade.get('entry_price2', 'N/A'):.2f}",
f"{trade.get('exit_price1', 'N/A'):.2f}",
f"{trade.get('exit_price2', 'N/A'):.2f}",
trade.get('exit_type', 'N/A'),
trade.get('exit_reason', 'N/A')
])
headers = ["Entry Date", "Exit Date", "Days Held", "PnL", "PnL %",
"Entry Price 1", "Entry Price 2", "Exit Price 1", "Exit Price 2", "Exit Type", "Exit Reason"]
print("\nTrade History:")
print(tabulate(trade_data, headers=headers, tablefmt="grid"))
def plot_equity_curve(self):
if not self.results:
print("No results available. Make sure to run the backtest first.")
return
strat = self.results[0]
if not hasattr(strat, 'equity_curve'):
print("No equity curve data found in the strategy.")
return
# Convert equity curve to pandas Series
equity_curve = pd.Series(strat.equity_curve, index=self.df1.index[:len(strat.equity_curve)])
# Calculate drawdown
drawdown = (equity_curve.cummax() - equity_curve) / equity_curve.cummax()
# Create figure with two subplots
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), gridspec_kw={'height_ratios': [3, 1]})
fig.suptitle('Equity Curve and Drawdown', fontsize=16)
# Plot equity curve
ax1.plot(equity_curve.index, equity_curve.values, label='Equity Curve', color='blue')
ax1.set_title('Equity Curve')
ax1.set_ylabel('Portfolio Value')
ax1.legend()
ax1.grid(True)
# Plot drawdown
ax2.fill_between(drawdown.index, drawdown.values, 0, alpha=0.3, color='red', label='Drawdown')
ax2.set_title('Drawdown')
ax2.set_ylabel('Drawdown')
ax2.set_xlabel('Date')
ax2.legend()
ax2.grid(True)
# Format x-axis
plt.gcf().autofmt_xdate()
# Add strategy performance metrics as text
metrics = self.get_metrics()
metrics_text = (f"Total Return: {metrics['Total Return (%)']:.2f}%\n"
f"Sharpe Ratio: {metrics['Sharpe Ratio']:.2f}\n"
f"Max Drawdown: {metrics['Max Drawdown (%)']:.2f}%\n"
f"Win Rate: {metrics['Win Rate (%)']:.2f}%")
fig.text(0.02, 0.02, metrics_text, fontsize=10, va='bottom')
# Adjust layout
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# Show plot
plt.show()
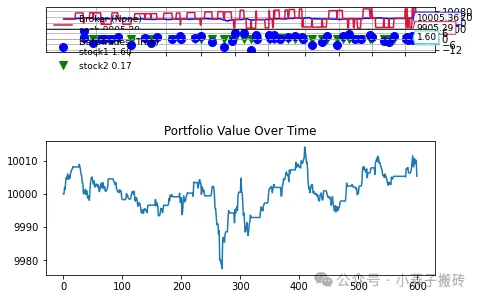
def plot_results(self):
if not self.results:
print("No results available. Make sure to run the backtest first.")
return
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
self.cerebro.plot(style='candlestick')
plt.title('Backtest Results')
plt.subplot(2, 1, 2)
strat = self.results[0]
if hasattr(strat, 'equity_curve'):
plt.plot(strat.equity_curve)
plt.title('Portfolio Value Over Time')
else:
print("No equity curve data found in the strategy.")
plt.tight_layout()
plt.show()
import pandas as pd
import numpy as np
def main():
# Define all parameters
params = {
# Data parameters
'stock1': "600941.ss",
'stock2': "601398.ss",
'start_date': '2021-01-01',
'end_date': '2024-07-29',
# Strategy parameters
'lookback': 20,
'entry_threshold': 1.5,
'stoploss_factor': 2.0,
'kappa': 0.06,
'half_life': 12.25,
# Backtest parameters
'initial_capital': 100000,
'commission': 0.001, # 0.1% commission
}
# Load data
df1 = pd.read_csv(f'stock_data/{params["stock1"]}.csv', index_col='Date', parse_dates=True)
df2 = pd.read_csv(f'stock_data/{params["stock2"]}.csv', index_col='Date', parse_dates=True)
# Ensure both stocks have the same date range
common_dates = df1.index.intersection(df2.index)
df1 = df1.loc[common_dates]
df2 = df2.loc[common_dates]
# Calculate Kappa and Half-Life if not provided
if params['kappa'] is None or params['half_life'] is None:
params['kappa'], params['half_life'] = calculate_kappa_and_half_life(df1, df2)
print(f"Calculated Kappa: {params['kappa']:.2f}")
print(f"Calculated Half-Life: {params['half_life']:.2f}")
# Create BacktestEngine instance
engine = BacktestEngine(
strategy_class=PairTradingStrategy,
df1=df1,
df2=df2,
initial_capital=params['initial_capital']
)
# Set strategy parameters
engine.set_strategy(
lookback=params['lookback'],
entry_threshold=params['entry_threshold'],
stoploss_factor=params['stoploss_factor'],
# kappa=params['kappa'],
half_life=params['half_life'],
stock1="stock1",
stock2="stock2"
)
# Set broker parameters
engine.set_broker(commission=params['commission'], initial_capital=params['initial_capital'])
# Run the backtest
engine.run()
# # print trade table
# engine.print_trade_table()
# Get and print metrics
engine.print_metrics()
# Plot the equity curve
engine.plot_equity_curve()
# Plot the results
engine.plot_results()
if __name__ == "__main__":
main()
from skopt import gp_minimize
from skopt.space import Real, Integer
from skopt.utils import use_named_args
def objective(params, df1, df2, initial_capital=100000, commission=0.001):
lookback, entry_threshold, stoploss_factor, holding_time_factor, half_life = params
engine = BacktestEngine(
strategy_class=PairTradingStrategy,
df1=df1,
df2=df2,
initial_capital=initial_capital
)
engine.set_strategy(
lookback=int(lookback),
entry_threshold=entry_threshold,
stoploss_factor=stoploss_factor,
holding_time_factor=holding_time_factor,
half_life=half_life,
stock1="stock1",
stock2="stock2"
)
engine.set_broker(commission=commission, initial_capital=initial_capital)
engine.run()
metrics = engine.get_metrics()
# We want to maximize Sharpe Ratio, so we return its negative
return -metrics.get('Sharpe Ratio', 0)
def bayesian_optimization(df1, df2, param_ranges, n_calls=50, initial_capital=100000, commission=0.001):
space = [
Integer(param_ranges['lookback'][0].min(), param_ranges['lookback'][0].max(), name='lookback'),
Real(param_ranges['entry_threshold'][0].min(), param_ranges['entry_threshold'][0].max(), name='entry_threshold'),
Real(param_ranges['stoploss_factor'][0].min(), param_ranges['stoploss_factor'][0].max(), name='stoploss_factor'),
Real(param_ranges['holding_time_factor'][0].min(), param_ranges['holding_time_factor'][0].max(), name='holding_time_factor'),
]
fixed_half_life = param_ranges['half_life'][0]
@use_named_args(space)
def objective_wrapper(**params):
params_list = list(params.values()) + [fixed_half_life]
return objective(params_list, df1, df2, initial_capital, commission)
def callback(res):
n = len(res.x_iters)
print(f"Optimization progress: {n / n_calls * 100:.2f}%")
result = gp_minimize(objective_wrapper, space, n_calls=n_calls, random_state=42, callback=callback)
best_params = {
'lookback': int(result.x[0]),
'entry_threshold': result.x[1],
'stoploss_factor': result.x[2],
'holding_time_factor': result.x[3],
'half_life': fixed_half_life
}
return best_params, -result.fun # Return best parameters and best Sharpe Ratio
import yfinance as yf
import numpy as np
def main():
# Find the best pair for pair trading
print("*" * 50)
print("Finding the best pair for pair trading...")
best_pair, suitable_pairs = find_best_pair(list_tickers)
print("Completed pair analysis.")
print("*" * 50)
if best_pair is None:
print("No suitable pairs found for pair trading.")
return
# get the best pair
stock1 = best_pair['stock1']
stock2 = best_pair['stock2']
# Download stock data
start_date = "2021-01-01"
end_date = "2024-07-29"
df1 = yf.download(stock1, start=start_date, end=end_date)
df2 = yf.download(stock2, start=start_date, end=end_date)
# Calculate kappa and half life
kappa, half_life = calculate_kappa_and_half_life(df1, df2, plot=False)
# Print CONFIG before optimization
print("*" * 50)
print("Stock Pair for Pair Trading:")
print(f'Stock 1: {stock1}')
print(f'Stock 2: {stock2}')
print(f'Kappa: {kappa:.2f}')
print(f'Half-Life: {half_life:.2f}')
print("*" * 50)
# Define parameter ranges for Bayesian optimization
look_back_range = np.arange(5, 31, 1)
entry_threshold_range = np.arange(1.5, 3.1, 0.1)
stoploss_factor_range = np.arange(1.5, 3.1, 0.1)
holding_time_factor_range = np.arange(1.0, 2.1, 0.1)
param_ranges = {
'lookback': [look_back_range],
'entry_threshold': [entry_threshold_range],
'stoploss_factor': [stoploss_factor_range],
'holding_time_factor': [holding_time_factor_range],
'half_life': [half_life]
}
# Run Bayesian optimization
best_params, best_sharpe = bayesian_optimization(df1, df2, param_ranges, n_calls=50)
print("*" * 50)
print("\nBest parameters found:")
for key, value in best_params.items():
print(f"{key}: {value}")
print(f"Best Sharpe Ratio: {best_sharpe}")
print("*" * 50)
# Run final backtest with best parameters
final_engine = BacktestEngine(
strategy_class=PairTradingStrategy,
df1=df1,
df2=df2,
initial_capital=100000
)
final_engine.set_strategy(**best_params, stock1="stock1", stock2="stock2")
final_engine.set_broker(commission=0.001, initial_capital=100000)
final_engine.run()
print("*" * 50)
print("\nFinal Backtest Results:")
final_engine.print_metrics()
final_engine.plot_equity_curve()
if __name__ == "__main__":
main()