什么是马尔可夫过程
马尔可夫过程,是因俄国数学家Andrey Andreyevich Markov得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马尔可夫性质。马尔科夫链作为实际过程的统计模型具有许多应用。
具体来说,马尔可夫过程包含以下几个关键概念:
1. 状态空间(State Space):这是所有可能状态的集合,可以是有限的或者无限的。
2. 转移概率(Transition Probabilities):每个状态转移都有一个相关的概率,描述了在下一时间点或状态下,系统从一个状态转移到另一个状态的概率。
3. 马尔可夫性质(Markov Property):如果一个随机过程在给定当前状态的情况下,未来的状态转移只依赖于当前状态,而与过去的状态历史无关,那么这个过程就具有马尔可夫性质。这可以数学上表达为:

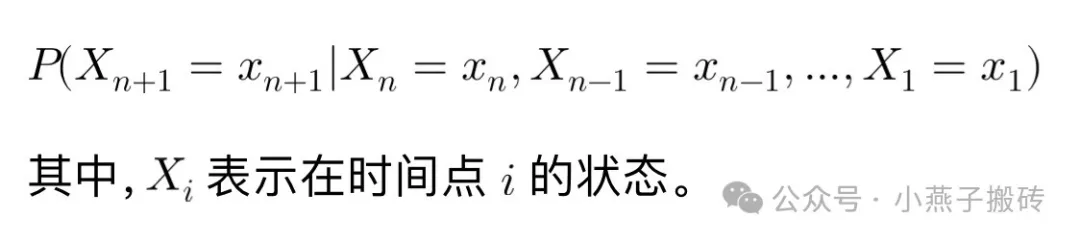
4. 初始分布(Initial Distribution):这是过程开始时,系统处于各个可能状态的概率分布。
5. 齐次性(Homogeneity):在某些类型的马尔可夫过程中,转移概率不随时间变化,即转移概率矩阵在每个时间步骤中都是相同的。
6. 遍历性(Ergodicity):如果一个马尔可夫过程最终能够探索到所有可能的状态,那么这个过程被称为遍历的。遍历性意味着长期行为不依赖于初始状态。
7. 稳态分布(Steady-state Distribution):对于遍历的马尔可夫过程,随着时间的推移,状态分布可能会趋于一个固定的概率分布,这个分布称为稳态分布。
马尔可夫过程在多个领域都有应用,包括物理学、化学、经济学、金融学、统计学、计算机科学等。例如,在金融市场分析中,马尔可夫过程可以用来模拟股票价格的随机波动;在语言模型中,可以用来预测文本中单词序列的出现概率。
发展历史
1906年,Andrey Andreyevich Markov为了描述随机过程首次提出了马尔科夫链,并应用在俄语字符序列的计算中。在随后的半个世纪中,该概念深刻影响了数学,统计,计算机,物理学,生物学,语言学等各个领域,并引申发展出了马尔可夫毯,马尔可夫模型,马尔可夫随机场等多种重要概念。
大名鼎鼎的MCMC本质上是将马尔可夫链用于对蒙特卡洛方法的积分过程中,由梅特罗波利斯于1953年在洛斯阿拉莫斯国家实验室提出。那时美国洛斯阿拉莫斯是当时少数几个拥有大规模计算机的城市,梅特罗波利斯则利用这种计算优势,在蒙特卡洛方法的基础上引入马尔可夫链,用于模拟某种液体在气化之后的平衡状态。1984年Stuart和Donald Geman兄弟对吉布斯采样进行了描述,形成了我们今天所熟悉的版本,而吉布斯采样就是一种简单且广泛适用的马尔可夫链蒙特卡洛(MCMC)算法。
时间再倒回一点,1957年,RICHARD BELLMAN提出了马尔可夫决策过程,这是基于马尔可夫过程理论的随机动态系统的最优决策过程,而马尔可夫过程的原始模型就是马尔科夫链。1980年,《Markov random fields and their applications》出版,详细描述了马尔可夫随机场的理论和应用,马尔可夫随机场实际上是马尔可夫过程的一个多维版本。1988年,Judea Pearl在其著作Probabilistic reasoning in intelligent systems: networks of plausible inference中提出了马尔可夫毯的概念。1991年,Lovejoy 研究了部分可观测马尔可夫决策过程(POMDP)。1995年D. P. Bertsekas 和 J. N. Tsitsiklis讨论了一类用于不确定条件下的控制和顺序决策的动态规划方法。 这些方法具有处理长期以来由于状态空间较大或缺乏准确模型而难以处理的问题的潜力,他们将规划所基于的环境表述为马尔可夫决策过程,这即是目前深度学习领域流行的强化学习的雏形。
1966年起,Leonard E. Baum等学者在一系列研究中提出了隐马尔可夫模型(Hidden Markov Model,HMM),它用来描述一个含有隐含未知参数的马尔可夫过程。1975年,Baker 将 HMM 用于语音识别,从那以后,HMM成为了大多数现代自动语音识别系统的基础。20世纪80年代起,HMM 也开始用于分析生物序列(DNA)。
在经济金融领域,James D. Hamilton 1989年机应用了制转换模型,其中马尔科夫链用来对高GDP增长速度时期与低GDP增长速度时期(换言之,经济扩张与紧缩)的转换进行建模。S.Brin和L.Page提出的谷歌所使用的网页排序算法(PageRank)(1998年),也是由马尔可夫链定义的。如果N是已知的网页数量,一个页面i有k_i个链接到这个页面,那么它到链接页面的转换概率为\alpha/k_i+(1-\alpha)/N,到未链接页面的概率为(1-\alpha)/N, 参数\alpha的取值大约为0.85。
在深度学习领域,Yoshua Bengio 等研究者于2017年提出了 GibbsNet,旨在通过匹配模型期望的联合分布和数据驱动的联合分布直接定义和学习转换算子(transition operator),然后使用转换算子训练图模型,成功将马尔科夫链与神经网络结合起来。同年,Jiaming Song, Shengjia Zhao和Stefano Ermon研究了生成对抗的训练方法来对马尔可夫链(Markov chain)的转移算子(transition operator)进行学习,目的是将其静态分布(stationary distribution)和目标数据分布相匹配。他们提出了一种新型的训练流程,以避免从静态分布中直接采样,但是仍然有能力逐渐达到目标分布。此模型可以从随机噪声开始,是无似然性的,并且能够在单步运行期间生成多个不同的样本。初步试验结果显示,当它临近其静态时,马尔可夫链可以生成高质量样本,即使是对于传统生成对抗网络相关理念中的较小结构亦是如此。
赌徒输光定律
有一个著名的定律,叫做“赌徒输光定律”。这个定律的意思是,一个有着赌本为n的赌徒去赌博,如果他贪婪成性,一直赌下去,那么总会在有限轮次后输光自己全部的赌本。
对这个定律的证明,即可以通过马尔可夫链得出结论。
假设赌徒和庄家对赌,赌徒的赌本为n,庄家的赌本为10n。在双方都不出老千的情况下,即每注的输赢概率都在1/2,双方一直赌下去,直到一方赌本归0,另一方赢者全得。
根据上述我们得到的结论,赌徒赌本为n,目标是赢取10n,其成为最后赢家的概率为Pn, 10n = 1/11;庄家赌本为10n,目标是赢取n,其成为最后赢家的概率为P10n, n = 10/11。由此可见庄家获胜的概率是赌徒获胜概率的10倍。
现实中,庄家的赌本要远远大于赌徒的赌本,所以只要赌徒一直赌下去,庄家赢光赌徒赌本的概率就非常非常大;换句话说,赌徒在有限轮次后输光自己赌本的概率也非常非常大。
但是股市与赌场还是有点区别的,看一个简单的股市里python例子加深理解,效果看起来不错。